 Русский
Русский English
EnglishCryptocurrencies:
8960 /
Markets: 118366
Market Cap: $ 3 146 398 586 015 /
24h Vol: $ 116 683 942 548 /
BTC
Dominance: 59.144869242535%
Классификация экзопланет (часть II построение моделей)
Это вторая и заключительная часть статьи, в которой мы рассматриваем задачу классификации экзопланет. Если предыдущая статья была больше про предобработку данных, то здесь мы будем строить модели, отбирать лучшие и экспериментировать.
P.S. некоторые моменты могут быть не понятны, поэтому лучше начать с первой части: https://habr.com/ru/articles/800999/
Итак я надеюсь что все кто хотел, посмотрели первую часть, поэтому можно начинать.
Случайный Лес
В тот раз мы отобрали признаки методом Gain, используя случайный лес, сейчас посмотрим, насколько эффективно было это делать, построив еще одну модель случайного леса.
rfi = RandomForestClassifier(max_depth=2, random_state=42)
rfi.fit(X_train[['koi_fpflag_nt', 'koi_fpflag_ss', 'koi_fpflag_co', 'koi_fpflag_ec',
'koi_depth', 'koi_prad', 'koi_prad_err1', 'koi_prad_err2', 'koi_teq',
'koi_insol_err1', 'koi_insol_err2', 'koi_model_snr', 'koi_steff_err1',
'koi_steff_err2']], y_train)
rfi_pred_train=rfi.predict(X_train[['koi_fpflag_nt', 'koi_fpflag_ss', 'koi_fpflag_co', 'koi_fpflag_ec',
'koi_depth', 'koi_prad', 'koi_prad_err1', 'koi_prad_err2', 'koi_teq',
'koi_insol_err1', 'koi_insol_err2', 'koi_model_snr', 'koi_steff_err1',
'koi_steff_err2']])
rfi_pred_test=rfi.predict(X_test[['koi_fpflag_nt', 'koi_fpflag_ss', 'koi_fpflag_co', 'koi_fpflag_ec',
'koi_depth', 'koi_prad', 'koi_prad_err1', 'koi_prad_err2', 'koi_teq',
'koi_insol_err1', 'koi_insol_err2', 'koi_model_snr', 'koi_steff_err1',
'koi_steff_err2']])На самом деле не очень красочно таскать с собой этот список из признаков, но я человек ленивый, увидел вывод признаков в Feature Selection, скопировал, добавил скобочки [квадратные] и вперед.
Посмотрим на метрики
metrics(y_test,rfi_pred_test)accuracy: 0.9456351280710925
f1: 0.94831013916501
roc auc: 0.9462939057241274
А че это за функция такая может спросить читатель, который не перешел на первую часть и поленился. Не осуждаю. Это функция и вот она:
def metrics(y_true,y_pred):
acc=accuracy_score(y_true, y_pred)
f1=f1_score(y_true, y_pred)
roc_auc=roc_auc_score(y_true, y_pred)
print(f'accuracy: {acc}\nf1: {f1}\nroc auc: {roc_auc} ')Поскольку мы будем строить больше чем несколько моделей наличие такой функции упрощает нам жизнь, инженерное решение, можно сказать)
Теперь вспомним про то, что еще мы использовали F-тест для отбора признаков, получили такой список: ['koi_fpflag_nt', 'koi_fpflag_ss', 'koi_fpflag_co', 'koi_fpflag_ec', 'koi_depth', 'koi_teq', 'koi_steff_err1', 'koi_steff_err2'] , с него просто забираем переменную X_f, которая объявлялась в коде первой части
y_f=y
X_f_train, X_f_test, y_f_train, y_f_test = train_test_split(X_f, y_f, test_size=0.2, random_state=42)
model_f=RandomForestClassifier(max_depth=2, random_state=42)
model_f.fit(X_f_train, y_f_train)
f_pred=model_f.predict(X_f_test)
metrics(y_f_test, f_pred)accuracy: 0.9790904338734971
f1: 0.9801192842942346
roc auc: 0.9798926657489797
Пока что F-test это самое лучшее что случалось с этими данными, мне очень нравятся такие метрики, но мы на этом не остановимся.
XGBoost

мемчик с интернета для того чтобы не было скучно
Прежде чем строить модель XGBoost, прогоним его через GridSearchCV, скорее всего это произойдет относительно быстро. Я просто отмечу, что чем больше параметров вы решили прогнать, тем больше времени это займет.
GridSearchCV позволяет отобрать лучшие параметры для обучения модели, по моим ощущениям у XGBoost данная функция работает быстрее чем у Catboost, как и в принципе процесс обучения. Возможно я не прав, поэтому если у кого то есть мысли на этот счет, хотелось бы их послушать.
Запускаем процесс:
from xgboost import XGBClassifier
from sklearn.model_selection import GridSearchCV
xgbmodel = XGBClassifier()
parameters = {'learning_rate': [0.03, 0.1],
'max_depth': [2,3.5, 10],
'colsample_bytree': [0.7, 0.5, 1],
'n_estimators': [0,150,10]}
xgb_grid = GridSearchCV(xgbmodel,
parameters,
cv = 2,
n_jobs = 5,
verbose=True)
xgb_grid.fit(X,y)
print(xgb_grid.best_score_)
print(xgb_grid.best_params_)На выходе получаем такое:
Fitting 2 folds for each of 54 candidates, totalling 108 fits 0.9807611877875366 {'colsample_bytree': 1, 'learning_rate': 0.03, 'max_depth': 2, 'n_estimators': 150}
записываем эти параметры в нашу модель XGBoost
xgb=XGBClassifier(n_estimators=150, learning_rate=0.1, max_depth=2, colsample_bytree=0.7 ,randomstate=0)
xgb.fit(X_f_train, y_f_train)
metrics(y_test, xgb.predict(X_f_test))accuracy: 0.9822268687924726
f1: 0.9831516352824579
roc auc: 0.982836728555653
Метрики лучше, чем у случайного леса, причем во всех 3-х построенных его вариациях.
Можно сверху накинуть Gain и уменьшить выборку, но как по мне 8 параметров и такие метрики это хорошее соотношение. Если у кого- то будет желание, думаю реализовать метод Gain по аналогии с Random-Forest (снова же предыдущая статья) не составит труда.
А мы делаем следующий шаг
CatBoost

Отбор параметров можно сделать и через Catboost, к тому же у него есть для этого свой метод, который еще и график прикольный строит, но вам придется ждать, а параметры XGBoost у нас уже есть и думаю никто не будет против, если мы их интегрируем в Catboost с небольшими изменениями:
from catboost import CatBoostClassifier
cat=CatBoostClassifier(n_estimators=150, learning_rate=0.1, max_depth=2,bootstrap_type='Bayesian', task_type='GPU')
cat.fit(X_f_train,y_f_train, verbose=False)
cat_pred=cat.predict(X_f_test)
metrics(y_test, cat_pred)Метрики:
accuracy: 0.9822268687924726
f1: 0.9831516352824579
roc auc: 0.982836728555653
Итак, с точки зрения классического ML мы реализовали наиболее популярные модели и получили как и ожидалось получили лучшие метрики на моделях градиентного бустинга.
Нейросеть на tensorflow
Теперь проверим поставленный тезис в I части о том, что можно эту задачу решить через нейронную сеть.
Для начала стандартизируем данные относительно нормального распределения
mean=X_train.mean(axis=0)
std=X_train.std(axis=0)
X_train-= mean
X_train/= std
X_test-= mean
X_test/= std
#запринтим что мы сделали
print('train mean',X_train.mean(axis=0)[:5])
print('test mean',X_test.mean(axis=0)[:5])
print('train std',X_train.std(axis=0)[:5])
print('train std',X_test.std(axis=0)[:5])std- среднеквадратичное отклонение
mean- среднее
Кстати std будет для всех равно 1 в print-е

Небольшое отступление
Для построения НС мы будем использовать tensorflow, который после версии 2.11 перестал поддерживать обучение на GPU на Windows, подробнее можно прочитать на их сайте: https://www.tensorflow.org/install/pip?hl=ru#windows-native_1
Чтобы решить данную проблему нужно установить python версии 3.9 (у меня 3.9.18), удалять текущий пайтон не нужно, но для версии 3.9 нужно создать отдельную виртуальную среду, например через miniconda, скачать CUDA и CUDNN если у вас NVidia, насчет альтернатив не знаю, так как у самого Nvidia. Все веселье с установкой состоит в том что нужно правильно подобрать версии всех этих расширений и библиотеки tensorflow. На это действительно может уйти много времени, если ранее вы ничего подобного не делали, поэтому дополнительно может помочь этот парень с ютуба, который заморочился и сделал подробную установку всех Cuda и Cudnn: https://www.youtube.com/watch?v=xTF_n1jp9n8
Однако о создании новой Venv ( виртуальной среды) он вроде не очень много говорил, поэтому тем кто ищет гугл в помощь.
Альтернатива всему этому либо обучение на CPU то есть на обычном процессоре, либо же google Colab, где можно выбрать на чем будет работать ваша среда и пользоваться плюшками сервиса. Для данной задачи их мощностей должно хватить.
Обучение на GPU явно быстрее чем на CPU, прирост в 1.5-2 раза можно получить точно.
На этом закончим отступление
Зададим параметры модели, а перед этим проверим, работает ли GPU
import tensorflow as tf
physical_devices = tf.config.list_physical_devices('GPU')
print("Num GPUs:", len(physical_devices))
#output: 1 если gpu работает
model = tf.keras.Sequential([
tf.keras.layers.Dense(32, activation='relu', input_shape=(X_train.shape[1],)),
tf.keras.layers.Dense(16, activation='relu' ),
tf.keras.layers.Dense(1, activation='sigmoid')
])
model.summary()
# Model: "sequential"
# _________________________________________________________________
# Layer (type) Output Shape Param #
# =================================================================
# dense (Dense) (None, 32) 1376
# dense_1 (Dense) (None, 16) 528
# dense_2 (Dense) (None, 1) 17
# =================================================================
# Total params: 1,921
# Trainable params: 1,921
# Non-trainable params: 0
# _________________________________________________________________Обучаем и смотрим на lossы
model.compile(optimizer='adam', loss='binary_crossentropy')
history = model.fit(X_train, y_train, epochs=16, verbose=1)
# Визуализация процесса обучения
plt.plot(history.history['loss'])
plt.xlim(-0.5,20)
plt.title('Loss')
plt.xlabel('Epoch')
plt.ylabel('Loss')
plt.show()
model loss
Воспользуемся Datageneratorом, позаимствованным у этого прекрасного автора с youtube: https://www.youtube.com/watch?v=PLlic60dgS4&list=PLkJJmZ1EJno4lRvtQjQrNNACpeMLOd-SD&index=7
В нем задается batch_size, поэтому если вы хотите получить результат поскорее, то просто увеличьте его например до 16, 32 или 48 и т.д. Качество модели упадет, но зато она быстрее построится.
import numpy as np
from tensorflow.keras.utils import Sequence
class DataGenerator(Sequence):
def __init__(self, data, labels, batch_size=1):
self.batch_size = batch_size
self.data = data
self.labels = labels
def __len__(self):
return int(np.round(len(self.data) / self.batch_size))
def __getitem__(self, index):
X = self.data[index * self.batch_size : (index+1) * self.batch_size]
y = self.labels[index * self.batch_size : (index+1) * self.batch_size]
return X, y
train_datagen = DataGenerator(X_train, y_train)
test_datagen = DataGenerator(X_test, y_test)
print(len(train_datagen))
print(len(test_datagen))Обучим еще одну нейронку с оценкой данных на валидации
from tensorflow.keras.callbacks import ModelCheckpoint
# Создаем коллбэк для выполнения оценки на валидационных данных
checkpoint = ModelCheckpoint(filepath='best_model.h5', save_best_only=True, save_weights_only=True)
# Обучение модели с выполнением оценки на валидационных данных
history = model.fit(train_datagen, epochs=16, batch_size=100, validation_data=test_datagen, callbacks=[checkpoint])
# Загрузка лучших весов модели
model.load_weights('best_model.h5')
plt.plot(history.history['loss'], label='train loss')
plt.plot(history.history['val_loss'], label='validation loss')
plt.legend( );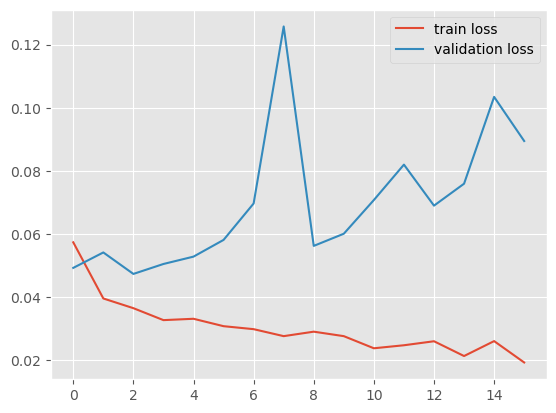
Ну такое себе, видимо не сегодня, tensorflow.
Можно покрутить параметры модели и возможно выйти на неплохие метрики, но эта игра не стоит свеч.
Бонус. Isolation Forest
Казалось бы мы сделали все что можно и после градиентного бустинга можно было остановиться и сказать что модель готова, но ради интереса можно рассмотреть Isolation Forest. Это метод обучения без учителя, который используется в задачах кластеризации и поиска аномалий.
from sklearn.ensemble import IsolationForest
clf = IsolationForest(max_samples=50, random_state=0)
clf.fit(X_f)
pred=clf.predict(X_f_test)
# на выход модель выдает либо 1 либо -1, для перехода к нашим параметрам, нужно переписать значения:
pred_processed = np.where(pred == -1, 0, pred)
pred_counts = pd.Series(pred_processed).value_counts()
# Строим график
pred_counts.plot(kind='barh', color=sns.palettes.mpl_palette('Dark2'))
plt.gca().spines[['top', 'right']].set_visible(False)
plt.title('Isolation Forest')
plt.xlim(0, pred_counts.max())
plt.show()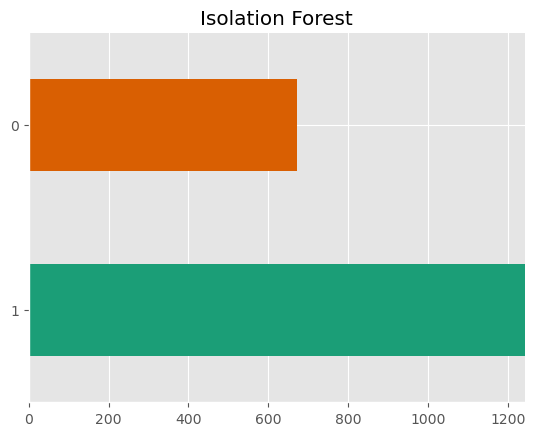
zeros_count = y_test[y_test == 0].count()
ones_count = y_test[y_test == 1].count()
print("Количество нулей в y_test:", zeros_count)
print("Количество единиц в y_test:", ones_count)Количество нулей в y_test: koi_pdisposition 894 dtype: int64
Количество единиц в y_test: koi_pdisposition 1019 dtype: int64
Можно прогнать его через метрики, но это не имеет особого смысла, ведь количество 0 в реальных данных примерно на 150-200 значений выше, чем у модели, да и в принципе подход метрик к задачам без учителя процесс сомнительный. Может быть мы получили совсем не то, что искали.
Вывод
Градиентный бустинг остается грозой Kaggle и является отличной моделью для решения данной задачи, которая справилась лучше чем НС. Причина как мне кажется в том, что данных для нейронки нужно на порядок больше и тогда она по другому заиграет и ожидание процесса обучения окупится. Я надеюсь, что последние 2 статьи заинтересовали определенный круг людей, как новичков, так и более опытных в data science, хотелось бы получить какой-то фидбэк по проделанной работе, или какие то советы по тому, как можно было бы улучшить результаты моделей.
-
 19.11.25 08:11
JuneWatkins
19.11.25 08:11
JuneWatkins
I’m June Watkins from California. I never thought I’d lose my life savings in Bitcoin. One wrong click, a fake wallet update, and $187,000 vanished in seconds. I cried for days, felt stupid, ashamed, and completely hopeless. But God wouldn’t let me stay silent or defeated. A friend sent me a simple message: “Contact Mbcoin Recovery Group, they specialize in this.” I was skeptical (there are so many scammers), but something in my spirit said “try.” I reached out to Mbcoin Recovery Group through their official site and within minutes their team responded with kindness and clarity. They walked with me step by step, and stayed in constant contact. Three days later, I watched in tears as every single Bitcoin returned to my wallet, 100% recovered. God turned my mess into a message and my shame into a testimony! If you’ve lost crypto and feel it’s gone forever, don’t give up. I’m living proof that recovery is possible. Thank you, Mbcoin Recovery Group, and thank You, Jesus, for never leaving me stranded. contact: (https://mbcoinrecoverygrou.wixsite.com/mb-coin-recovery) (Email: [email protected]) (Call Number: +1 346 954-1564)
-
 19.11.25 08:26
elizabethmadison
19.11.25 08:26
elizabethmadison
My name is Elizabeth Madison currently living in New York. There was a time I felt completely broken. I had trusted a fraudulent bitcoin investment organization, who turned out to be a fraudster. I sent money, believing their sweet words and promises on the interest rate I will get back in return, only to realize later that I’ve been scammed. On the day of withdrawal there was no money in my account. The pain hit deep. I couldn’t sleep, I kept asking myself how I could have been so careless, meanwhile my mom was battling with a stroke and the expenses were too much. For days, I cried and blamed myself. The betrayal, the disappointment and my mom's health issues all of this stress made me want to give up on life. But one day, I decided that sitting in pain wouldn’t solve anything. I picked myself up and chose to fight for what I lost then I came across GREAT WHIP RECOVERY CYBER SERVICES and saw how he helped people recover their funds from online fraud. I emailed all the transactions and paperwork I had with the fraudulent organization and they helped me recover all my lost money in just five days. If you have ever fallen victim to scammers, contact GREAT WHIP RECOVERY CYBER SERVICES to help you recover every penny you have lost. (Text +1(406)2729101) (Email [email protected])
-
19.11.25 08:27
elizabethmadison
My name is Elizabeth Madison currently living in New York. There was a time I felt completely broken. I had trusted a fraudulent bitcoin investment organization, who turned out to be a fraudster. I sent money, believing their sweet words and promises on the interest rate I will get back in return, only to realize later that I’ve been scammed. On the day of withdrawal there was no money in my account. The pain hit deep. I couldn’t sleep, I kept asking myself how I could have been so careless, meanwhile my mom was battling with a stroke and the expenses were too much. For days, I cried and blamed myself. The betrayal, the disappointment and my mom's health issues all of this stress made me want to give up on life. But one day, I decided that sitting in pain wouldn’t solve anything. I picked myself up and chose to fight for what I lost then I came across GREAT WHIP RECOVERY CYBER SERVICES and saw how he helped people recover their funds from online fraud. I emailed all the transactions and paperwork I had with the fraudulent organization and they helped me recover all my lost money in just five days. If you have ever fallen victim to scammers, contact GREAT WHIP RECOVERY CYBER SERVICES to help you recover every penny you have lost. (Text +1(406)2729101) Website https://greatwhiprecoveryc.wixsite.com/greatwhip-site (Email [email protected])
-
 19.11.25 16:30
marcushenderson624
19.11.25 16:30
marcushenderson624
Bitcoin Recovery Testimonial After falling victim to a cryptocurrency scam group, I lost $354,000 worth of USDT. I thought all hope was lost from the experience of losing my hard-earned money to scammers. I was devastated and believed there was no way to recover my funds. Fortunately, I started searching for help to recover my stolen funds and I came across a lot of testimonials online about Capital Crypto Recovery, an agent who helps in recovery of lost bitcoin funds, I contacted Capital Crypto Recover Service, and with their expertise, they successfully traced and recovered my stolen assets. Their team was professional, kept me updated throughout the process, and demonstrated a deep understanding of blockchain transactions and recovery protocols. They are trusted and very reliable with a 100% successful rate record Recovery bitcoin, I’m grateful for their help and highly recommend their services to anyone seeking assistance with lost crypto. Contact: [email protected] Phone CALL/Text Number: +1 (336) 390-6684 Email: [email protected] Website: https://recovercapital.wixsite.com/capital-crypto-rec-1
-
19.11.25 16:30
marcushenderson624
Bitcoin Recovery Testimonial After falling victim to a cryptocurrency scam group, I lost $354,000 worth of USDT. I thought all hope was lost from the experience of losing my hard-earned money to scammers. I was devastated and believed there was no way to recover my funds. Fortunately, I started searching for help to recover my stolen funds and I came across a lot of testimonials online about Capital Crypto Recovery, an agent who helps in recovery of lost bitcoin funds, I contacted Capital Crypto Recover Service, and with their expertise, they successfully traced and recovered my stolen assets. Their team was professional, kept me updated throughout the process, and demonstrated a deep understanding of blockchain transactions and recovery protocols. They are trusted and very reliable with a 100% successful rate record Recovery bitcoin, I’m grateful for their help and highly recommend their services to anyone seeking assistance with lost crypto. Contact: [email protected] Phone CALL/Text Number: +1 (336) 390-6684 Email: [email protected] Website: https://recovercapital.wixsite.com/capital-crypto-rec-1
-
20.11.25 15:55
mariotuttle94
HIRE THE BEST HACKER ONLINE FOR CRYPTO BITCOIN SCAM RECOVERY / iFORCE HACKER RECOVERY After a security breach, my husband lost $133,000 in Bitcoin. We sought help from a professional cybersecurity team iForce Hacker Recovery they guided us through each step of the recovery process. Their expertise allowed them to trace the compromised funds and help us understand how the breach occurred. The experience brought us clarity, restored a sense of stability, and reminded us of the importance of strong digital asset and security practices. Website: ht tps:/ /iforcehackers. c om WhatsApp: +1 240-803-3706 Email: iforcehk @ consultant. c om
-
21.11.25 10:56
marcushenderson624
Bitcoin Recovery Testimonial After falling victim to a cryptocurrency scam group, I lost $354,000 worth of USDT. I thought all hope was lost from the experience of losing my hard-earned money to scammers. I was devastated and believed there was no way to recover my funds. Fortunately, I started searching for help to recover my stolen funds and I came across a lot of testimonials online about Capital Crypto Recovery, an agent who helps in recovery of lost bitcoin funds, I contacted Capital Crypto Recover Service, and with their expertise, they successfully traced and recovered my stolen assets. Their team was professional, kept me updated throughout the process, and demonstrated a deep understanding of blockchain transactions and recovery protocols. They are trusted and very reliable with a 100% successful rate record Recovery bitcoin, I’m grateful for their help and highly recommend their services to anyone seeking assistance with lost crypto. Contact: [email protected] Phone CALL/Text Number: +1 (336) 390-6684 Email: [email protected] Website: https://recovercapital.wixsite.com/capital-crypto-rec-1
-
21.11.25 10:56
marcushenderson624
Bitcoin Recovery Testimonial After falling victim to a cryptocurrency scam group, I lost $354,000 worth of USDT. I thought all hope was lost from the experience of losing my hard-earned money to scammers. I was devastated and believed there was no way to recover my funds. Fortunately, I started searching for help to recover my stolen funds and I came across a lot of testimonials online about Capital Crypto Recovery, an agent who helps in recovery of lost bitcoin funds, I contacted Capital Crypto Recover Service, and with their expertise, they successfully traced and recovered my stolen assets. Their team was professional, kept me updated throughout the process, and demonstrated a deep understanding of blockchain transactions and recovery protocols. They are trusted and very reliable with a 100% successful rate record Recovery bitcoin, I’m grateful for their help and highly recommend their services to anyone seeking assistance with lost crypto. Contact: [email protected] Phone CALL/Text Number: +1 (336) 390-6684 Email: [email protected] Website: https://recovercapital.wixsite.com/capital-crypto-rec-1
-
 22.11.25 04:41
VERONICAFREDDIE809
22.11.25 04:41
VERONICAFREDDIE809
Earlier this year, I made a mistake that changed everything. I downloaded what I thought was a legitimate trading app I’d found through a Telegram channel. At first, everything looked real until I tried to withdraw. My entire investment vanished into a bot account, and that’s when the truth hit me: I had been scammed. I can’t describe the feeling. It was as if the ground dropped out from under me. I blamed myself. I felt stupid, ashamed, helpless every painful emotion at once. For a while, I couldn’t even talk about it. I thought no one would understand. But then I got connected to the best female expert AGENT Jasmine Lopez,,( [email protected] ) ,She didn’t brush me off or judge me. She took my fear seriously. She followed leads I didn’t even know existed, and identified multiple off-chain indicators and wallet clusters linked to the scammer network, she helped me understand what had truly happened behind the scenes. For the first time since everything fell apart, I felt hope. Hearing that other people students, parents, hardworking people had been targeted the same way made me realize I wasn’t alone. What happened to us wasn’t stupidity. It was a coordinated attack. We were prey in a system built to deceive. And somehow, through all the chaos, Agent Jasmine stepped in and shined a light into the darkest moment of my life. I’m still healing from the experience. It changed me. But it also reminded me that even when you think you’re at the end, sometimes a lifeline appears where you least expect it. Contact her at [email protected] WhatsApp at +44 736-644-5035.
-
 22.11.25 22:04
wendytaylor015
22.11.25 22:04
wendytaylor015
My name is Wendy Taylor, I'm from Los Angeles, i want to announce to you Viewer how Capital Crypto Recover help me to restore my Lost Bitcoin, I invested with a Crypto broker without proper research to know what I was hoarding my hard-earned money into scammers, i lost access to my crypto wallet or had your funds stolen? Don’t worry Capital Crypto Recover is here to help you recover your cryptocurrency with cutting-edge technical expertise, With years of experience in the crypto world, Capital Crypto Recover employs the best latest tools and ethical hacking techniques to help you recover lost assets, unlock hacked accounts, Whether it’s a forgotten password, Capital Crypto Recover has the expertise to help you get your crypto back. a security company service that has a 100% success rate in the recovery of crypto assets, i lost wallet and hacked accounts. I provided them the information they requested and they began their investigation. To my surprise, Capital Crypto Recover was able to trace and recover my crypto assets successfully within 24hours. Thank you for your service in helping me recover my $647,734 worth of crypto funds and I highly recommend their recovery services, they are reliable and a trusted company to any individuals looking to recover lost money. Contact email [email protected] OR Telegram @Capitalcryptorecover Call/Text Number +1 (336)390-6684 his contact: [email protected] His website: https://recovercapital.wixsite.com/capital-crypto-rec-1
-
22.11.25 22:04
wendytaylor015
My name is Wendy Taylor, I'm from Los Angeles, i want to announce to you Viewer how Capital Crypto Recover help me to restore my Lost Bitcoin, I invested with a Crypto broker without proper research to know what I was hoarding my hard-earned money into scammers, i lost access to my crypto wallet or had your funds stolen? Don’t worry Capital Crypto Recover is here to help you recover your cryptocurrency with cutting-edge technical expertise, With years of experience in the crypto world, Capital Crypto Recover employs the best latest tools and ethical hacking techniques to help you recover lost assets, unlock hacked accounts, Whether it’s a forgotten password, Capital Crypto Recover has the expertise to help you get your crypto back. a security company service that has a 100% success rate in the recovery of crypto assets, i lost wallet and hacked accounts. I provided them the information they requested and they began their investigation. To my surprise, Capital Crypto Recover was able to trace and recover my crypto assets successfully within 24hours. Thank you for your service in helping me recover my $647,734 worth of crypto funds and I highly recommend their recovery services, they are reliable and a trusted company to any individuals looking to recover lost money. Contact email [email protected] OR Telegram @Capitalcryptorecover Call/Text Number +1 (336)390-6684 his contact: [email protected] His website: https://recovercapital.wixsite.com/capital-crypto-rec-1
-
22.11.25 22:05
wendytaylor015
My name is Wendy Taylor, I'm from Los Angeles, i want to announce to you Viewer how Capital Crypto Recover help me to restore my Lost Bitcoin, I invested with a Crypto broker without proper research to know what I was hoarding my hard-earned money into scammers, i lost access to my crypto wallet or had your funds stolen? Don’t worry Capital Crypto Recover is here to help you recover your cryptocurrency with cutting-edge technical expertise, With years of experience in the crypto world, Capital Crypto Recover employs the best latest tools and ethical hacking techniques to help you recover lost assets, unlock hacked accounts, Whether it’s a forgotten password, Capital Crypto Recover has the expertise to help you get your crypto back. a security company service that has a 100% success rate in the recovery of crypto assets, i lost wallet and hacked accounts. I provided them the information they requested and they began their investigation. To my surprise, Capital Crypto Recover was able to trace and recover my crypto assets successfully within 24hours. Thank you for your service in helping me recover my $647,734 worth of crypto funds and I highly recommend their recovery services, they are reliable and a trusted company to any individuals looking to recover lost money. Contact email [email protected] OR Telegram @Capitalcryptorecover Call/Text Number +1 (336)390-6684 his contact: [email protected] His website: https://recovercapital.wixsite.com/capital-crypto-rec-1
-
23.11.25 03:34
Matt Kegan
SolidBlock Forensics are absolutely the best Crypto forensics team, they're swift to action and accurate
-
23.11.25 09:54
elizabethrush89
God bless Capital Crypto Recover Services for the marvelous work you did in my life, I have learned the hard way that even the most sensible investors can fall victim to scams. When my USD was stolen, for anyone who has fallen victim to one of the bitcoin binary investment scams that are currently ongoing, I felt betrayal and upset. But then I was reading a post on site when I saw a testimony of Wendy Taylor online who recommended that Capital Crypto Recovery has helped her recover scammed funds within 24 hours. after reaching out to this cyber security firm that was able to help me recover my stolen digital assets and bitcoin. I’m genuinely blown away by their amazing service and professionalism. I never imagined I’d be able to get my money back until I complained to Capital Crypto Recovery Services about my difficulties and gave all of the necessary paperwork. I was astounded that it took them 12 hours to reclaim my stolen money back. Without a doubt, my USDT assets were successfully recovered from the scam platform, Thank you so much Sir, I strongly recommend Capital Crypto Recover for any of your bitcoin recovery, digital funds recovery, hacking, and cybersecurity concerns. You reach them Call/Text Number +1 (336)390-6684 His Email: [email protected] Contact Telegram: @Capitalcryptorecover Via Contact: [email protected] His website: https://recovercapital.wixsite.com/capital-crypto-rec-1
-
23.11.25 18:01
mosbygerry
I recently had the opportunity to work with a skilled programmer who specialized in recovering crypto assets, and the results were nothing short of impressive. The experience not only helped me regain control of my investments but also provided valuable insight into the intricacies of cryptocurrency technology and cybersecurity. The journey began when I attempted to withdraw $183,000 from an investment firm, only to encounter a series of challenges that made it impossible for me to access my funds. Despite seeking assistance from individuals claiming to be Bitcoin miners, I was unable to recover my investments. The situation was further complicated by the fact that all my deposits were made using various cryptocurrencies that are difficult to trace. However, I persisted in my pursuit of recovery, driven by the determination to reclaim my losses. It was during this time that I discovered TechY Force Cyber Retrieval, a team of experts with a proven track record of successfully recovering crypto assets. With their assistance, I was finally able to recover my investments, and in doing so, gained a deeper understanding of the complex mechanisms that underpin cryptocurrency transactions. The experience taught me that with the right expertise and guidance, even the most seemingly insurmountable challenges can be overcome. I feel a sense of obligation to share my positive experience with others who may have fallen victim to cryptocurrency scams or are struggling to recover their investments. If you find yourself in a similar situation, I highly recommend seeking the assistance of a trustworthy and skilled programmer, such as those at TechY Force Cyber Retrieval. WhatsApp (+1561726 3697) or (+1561726 3697). Their expertise and dedication to helping individuals recover their crypto assets are truly commendable, and I have no hesitation in endorsing their services to anyone in need. By sharing my story, I hope to provide a beacon of hope for those who may have lost faith in their ability to recover their investments and to emphasize the importance of seeking professional help when navigating the complex world of cryptocurrency.
-
24.11.25 11:43
michaeldavenport238
I was recently scammed out of $53,000 by a fraudulent Bitcoin investment scheme, which added significant stress to my already difficult health issues, as I was also facing cancer surgery expenses. Desperate to recover my funds, I spent hours researching and consulting other victims, which led me to discover the excellent reputation of Capital Crypto Recover, I came across a Google post It was only after spending many hours researching and asking other victims for advice that I discovered Capital Crypto Recovery’s stellar reputation. I decided to contact them because of their successful recovery record and encouraging client testimonials. I had no idea that this would be the pivotal moment in my fight against cryptocurrency theft. Thanks to their expert team, I was able to recover my lost cryptocurrency back. The process was intricate, but Capital Crypto Recovery's commitment to utilizing the latest technology ensured a successful outcome. I highly recommend their services to anyone who has fallen victim to cryptocurrency fraud. For assistance contact [email protected] and on Telegram OR Call Number +1 (336)390-6684 via email: [email protected] you can visit his website: https://recovercapital.wixsite.com/capital-crypto-rec-1
-
24.11.25 11:43
michaeldavenport238
I was recently scammed out of $53,000 by a fraudulent Bitcoin investment scheme, which added significant stress to my already difficult health issues, as I was also facing cancer surgery expenses. Desperate to recover my funds, I spent hours researching and consulting other victims, which led me to discover the excellent reputation of Capital Crypto Recover, I came across a Google post It was only after spending many hours researching and asking other victims for advice that I discovered Capital Crypto Recovery’s stellar reputation. I decided to contact them because of their successful recovery record and encouraging client testimonials. I had no idea that this would be the pivotal moment in my fight against cryptocurrency theft. Thanks to their expert team, I was able to recover my lost cryptocurrency back. The process was intricate, but Capital Crypto Recovery's commitment to utilizing the latest technology ensured a successful outcome. I highly recommend their services to anyone who has fallen victim to cryptocurrency fraud. For assistance contact [email protected] and on Telegram OR Call Number +1 (336)390-6684 via email: [email protected] you can visit his website: https://recovercapital.wixsite.com/capital-crypto-rec-1
-
24.11.25 16:34
Mundo
I wired 120k in crypto to the wrong wallet. One dumb slip-up, and poof gone. That hit me hard. Lost everything I had built up. Crypto moves on the blockchain. It's like a public record book. Once you send, that's it. No take-backs. Banks can fix wire mistakes. Not here. Transfers stick forever. a buddy tipped me off right away. Meet Sylvester Bryant. Guy's a pro at pulling back lost crypto. Handles cases others can't touch, he spots scammer moves cold. Follows money down secret paths. Mixers. Fake trades. Hidden swaps. You name it, he tracks it. this happens to tons of folks. Fat-finger a key. Miss one digit in the address. Boom. Billions vanish like that each year. I panicked. Figured my stash was toast for good. Bryant flipped the script. He jumps on hard jobs quick. Digs deep. Cracks the trail. Got my funds back safe. You're in the same boat? Don't sit there. Hit him up today. Email [email protected]. WhatsApp +1 512 577 7957. Or +44 7428 662701. Time's your enemy here. Scammers spend fast. Chains churn non-stop. Move now. Grab your cash back home.
-
25.11.25 05:15
michaeldavenport218
I was recently scammed out of $53,000 by a fraudulent Bitcoin investment scheme, which added significant stress to my already difficult health issues, as I was also facing cancer surgery expenses. Desperate to recover my funds, I spent hours researching and consulting other victims, which led me to discover the excellent reputation of Capital Crypto Recover, I came across a Google post It was only after spending many hours researching and asking other victims for advice that I discovered Capital Crypto Recovery’s stellar reputation. I decided to contact them because of their successful recovery record and encouraging client testimonials. I had no idea that this would be the pivotal moment in my fight against cryptocurrency theft. Thanks to their expert team, I was able to recover my lost cryptocurrency back. The process was intricate, but Capital Crypto Recovery's commitment to utilizing the latest technology ensured a successful outcome. I highly recommend their services to anyone who has fallen victim to cryptocurrency fraud. For assistance contact [email protected] and on Telegram OR Call Number +1 (336)390-6684 via email: [email protected] you can visit his website: https://recovercapital.wixsite.com/capital-crypto-rec-1
-
25.11.25 13:31
mickaelroques52
CRYPTO TRACING AND INVESTIGATION EXPERT: HOW TO RECOVER STOLEN CRYPTO_HIRE RAPID DIGITAL RECOVERY
-
25.11.25 13:31
mickaelroques52
I’ve always considered myself a careful person when it comes to money, but even the most cautious people can be fooled. A few months ago, I invested some of my Bitcoin into what I believed was a legitimate platform. Everything seemed right, professional website, live chat support and even convincing testimonials. I thought I had done my homework. But when I tried to withdraw my funds, everything fell apart. My account was blocked, the so-called support team disappeared and I realized I had been scammed. The shock was overwhelming. I couldn’t believe I had fallen for it. That Bitcoin represented years of savings and sacrifices and it felt like everything had been stolen from me in seconds. I didn’t sleep for days and I was angry at myself for trusting the wrong people. In my desperation, I started searching for solutions and came across Rapid Digital Recovery. At first, I thought it was just another promise that would lead nowhere. But after speaking with them, I realized this was different. They were professional, clear and understanding. They explained exactly how they track stolen funds through blockchain forensics and what steps would be taken in my case. I gave them all the transaction details and they immediately got to work. What impressed me most was their transparency, they gave me updates regularly and kept me involved in the process. After weeks of investigation, they achieved what I thought was impossible: they recovered my stolen Bitcoin and safely returned it to my wallet. The relief I felt that day is indescribable. I went from feeling hopeless and broken to feeling like I had been given a second chance. I am forever grateful to Rapid Digital Recovery. They didn’t just recover my money, they restored my peace of mind. If you’re reading this because you’ve been scammed, please know you’re not alone and that recovery is possible. I’m living proof that with the right help, you can get your funds back... Contact Info Below WhatSapp: + 1 414 807 1485 Email: rapiddigitalrecovery (@) execs. com Telegram: + 1 680 5881 631
-
 26.11.25 18:18
harristhomas7376
26.11.25 18:18
harristhomas7376
"In the crypto world, this is great news I want to share. Last year, I fell victim to a scam disguised as a safe investment option. I have invested in crypto trading platforms for about 10yrs thinking I was ensuring myself a retirement income, only to find that all my assets were either frozen, I believed my assets were secure — until I discovered that my BTC funds had been frozen and withdrawals were impossible. It was a devastating moment when I realized I had been scammed, and I thought my Bitcoin was gone forever, Everything changed when a close friend recommended the Capital Crypto Recover Service. Their professionalism, expertise, and dedication enabled me to recover my lost Bitcoin funds back — more than €560.000 DEM to my BTC wallet. What once felt impossible became a reality thanks to their support. If you have lost Bitcoin through scams, hacking, failed withdrawals, or similar challenges, don’t lose hope. I strongly recommend Capital Crypto Recover Service to anyone seeking a reliable and effective solution for recovering any wallet assets. They have a proven track record of successful reputation in recovering lost password assets for their clients and can help you navigate the process of recovering your funds. Don’t let scammers get away with your hard-earned money – contact Email: [email protected] Phone CALL/Text Number: +1 (336) 390-6684 Contact: [email protected] Website: https://recovercapital.wixsite.com/capital-crypto-rec-1
-
26.11.25 18:20
harristhomas7376
"In the crypto world, this is great news I want to share. Last year, I fell victim to a scam disguised as a safe investment option. I have invested in crypto trading platforms for about 10yrs thinking I was ensuring myself a retirement income, only to find that all my assets were either frozen, I believed my assets were secure — until I discovered that my BTC funds had been frozen and withdrawals were impossible. It was a devastating moment when I realized I had been scammed, and I thought my Bitcoin was gone forever, Everything changed when a close friend recommended the Capital Crypto Recover Service. Their professionalism, expertise, and dedication enabled me to recover my lost Bitcoin funds back — more than €560.000 DEM to my BTC wallet. What once felt impossible became a reality thanks to their support. If you have lost Bitcoin through scams, hacking, failed withdrawals, or similar challenges, don’t lose hope. I strongly recommend Capital Crypto Recover Service to anyone seeking a reliable and effective solution for recovering any wallet assets. They have a proven track record of successful reputation in recovering lost password assets for their clients and can help you navigate the process of recovering your funds. Don’t let scammers get away with your hard-earned money – contact Email: [email protected] Phone CALL/Text Number: +1 (336) 390-6684 Contact: [email protected] Website: https://recovercapital.wixsite.com/capital-crypto-rec-1
-
26.11.25 19:13
James Robert
I am James Robert from Chicago. Few months ago, I fell victim to an online Bitcoin investment scheme that promised high returns within a short period. At first, everything seemed legitimate, their website looked professional, and the people behind it were very convincing. I invested a significant amount of money about $440,000 with the way they talk to me into investing on their bitcoin platform. Two months later I realized that it was a scam when I could no longer have access to my account and couldn’t withdraw my money. At first, I lost hope that I wouldn't be able to get my money back, I cried and was angry at how I even fell victim to a scam. For days after doing some research and seeking professional help online, I came across GREAT WHIP RECOVERY CYBER SERVICES and saw how they have helped people recover their money back from scammers. I reported the case immediately to them and gather every transaction detail, documentation and sent it to them. Today, I’m very happy because the GREAT WHIP RECOVERY CYBER SERVICES help me recover all my money I was scammed. You can contact GREAT WHIP RECOVERY CYBER SERVICES if you have ever fallen victim to scam. Email: [email protected] or Website https://greatwhiprecoveryc.wixsite.com/greatwhip-site
-
26.11.25 19:13
James Robert
I am James Robert from Chicago. Few months ago, I fell victim to an online Bitcoin investment scheme that promised high returns within a short period. At first, everything seemed legitimate, their website looked professional, and the people behind it were very convincing. I invested a significant amount of money about $440,000 with the way they talk to me into investing on their bitcoin platform. Two months later I realized that it was a scam when I could no longer have access to my account and couldn’t withdraw my money. At first, I lost hope that I wouldn't be able to get my money back, I cried and was angry at how I even fell victim to a scam. For days after doing some research and seeking professional help online, I came across GREAT WHIP RECOVERY CYBER SERVICES and saw how they have helped people recover their money back from scammers. I reported the case immediately to them and gather every transaction detail, documentation and sent it to them. Today, I’m very happy because the GREAT WHIP RECOVERY CYBER SERVICES help me recover all my money I was scammed. You can contact GREAT WHIP RECOVERY CYBER SERVICES if you have ever fallen victim to scam. Email: [email protected] or Website https://greatwhiprecoveryc.wixsite.com/greatwhip-site
-
26.11.25 19:13
James Robert
I am James Robert from Chicago. Few months ago, I fell victim to an online Bitcoin investment scheme that promised high returns within a short period. At first, everything seemed legitimate, their website looked professional, and the people behind it were very convincing. I invested a significant amount of money about $440,000 with the way they talk to me into investing on their bitcoin platform. Two months later I realized that it was a scam when I could no longer have access to my account and couldn’t withdraw my money. At first, I lost hope that I wouldn't be able to get my money back, I cried and was angry at how I even fell victim to a scam. For days after doing some research and seeking professional help online, I came across GREAT WHIP RECOVERY CYBER SERVICES and saw how they have helped people recover their money back from scammers. I reported the case immediately to them and gather every transaction detail, documentation and sent it to them. Today, I’m very happy because the GREAT WHIP RECOVERY CYBER SERVICES help me recover all my money I was scammed. You can contact GREAT WHIP RECOVERY CYBER SERVICES if you have ever fallen victim to scam. Email: [email protected] or Website https://greatwhiprecoveryc.wixsite.com/greatwhip-site
-
27.11.25 10:56
harristhomas7376
"In the crypto world, this is great news I want to share. Last year, I fell victim to a scam disguised as a safe investment option. I have invested in crypto trading platforms for about 10yrs thinking I was ensuring myself a retirement income, only to find that all my assets were either frozen, I believed my assets were secure — until I discovered that my BTC funds had been frozen and withdrawals were impossible. It was a devastating moment when I realized I had been scammed, and I thought my Bitcoin was gone forever, Everything changed when a close friend recommended the Capital Crypto Recover Service. Their professionalism, expertise, and dedication enabled me to recover my lost Bitcoin funds back — more than €560.000 DEM to my BTC wallet. What once felt impossible became a reality thanks to their support. If you have lost Bitcoin through scams, hacking, failed withdrawals, or similar challenges, don’t lose hope. I strongly recommend Capital Crypto Recover Service to anyone seeking a reliable and effective solution for recovering any wallet assets. They have a proven track record of successful reputation in recovering lost password assets for their clients and can help you navigate the process of recovering your funds. Don’t let scammers get away with your hard-earned money – contact Email: [email protected] Phone CALL/Text Number: +1 (336) 390-6684 Contact: [email protected] Website: https://recovercapital.wixsite.com/capital-crypto-rec-1
-
27.11.25 10:56
harristhomas7376
"In the crypto world, this is great news I want to share. Last year, I fell victim to a scam disguised as a safe investment option. I have invested in crypto trading platforms for about 10yrs thinking I was ensuring myself a retirement income, only to find that all my assets were either frozen, I believed my assets were secure — until I discovered that my BTC funds had been frozen and withdrawals were impossible. It was a devastating moment when I realized I had been scammed, and I thought my Bitcoin was gone forever, Everything changed when a close friend recommended the Capital Crypto Recover Service. Their professionalism, expertise, and dedication enabled me to recover my lost Bitcoin funds back — more than €560.000 DEM to my BTC wallet. What once felt impossible became a reality thanks to their support. If you have lost Bitcoin through scams, hacking, failed withdrawals, or similar challenges, don’t lose hope. I strongly recommend Capital Crypto Recover Service to anyone seeking a reliable and effective solution for recovering any wallet assets. They have a proven track record of successful reputation in recovering lost password assets for their clients and can help you navigate the process of recovering your funds. Don’t let scammers get away with your hard-earned money – contact Email: [email protected] Phone CALL/Text Number: +1 (336) 390-6684 Contact: [email protected] Website: https://recovercapital.wixsite.com/capital-crypto-rec-1
-
 27.11.25 20:04
deborah113
27.11.25 20:04
deborah113
Scammed Crypto Asset Recovery Solution Hire iFORCE HACKER RECOVERY When I traded online, I lost both my investment money and the anticipated gains. Before permitting any withdrawals, the site kept requesting more money, and soon I recognized I had been duped. It was really hard to deal with the loss after their customer service ceased responding. I saw a Facebook testimonial about how iForce Hacker Recovery assisted a victim of fraud in getting back the bitcoin she had transferred to con artists. I contacted iForce Hacker Recovery, submitted all relevant case paperwork, and meticulously followed the guidelines. I'm relieved that I was eventually able to get my money back, including the gains that were initially displayed on my account. I'm sharing my story to let others who have been conned know that you can recover your money. WhatsApp: +1 240-803-3706 Email: iforcehk @ consultant. c om Website: ht tps:/ /iforcehackers. c om
-
27.11.25 23:48
elizabethrush89
God bless Capital Crypto Recover Services for the marvelous work you did in my life, I have learned the hard way that even the most sensible investors can fall victim to scams. When my USD was stolen, for anyone who has fallen victim to one of the bitcoin binary investment scams that are currently ongoing, I felt betrayal and upset. But then I was reading a post on site when I saw a testimony of Wendy Taylor online who recommended that Capital Crypto Recovery has helped her recover scammed funds within 24 hours. after reaching out to this cyber security firm that was able to help me recover my stolen digital assets and bitcoin. I’m genuinely blown away by their amazing service and professionalism. I never imagined I’d be able to get my money back until I complained to Capital Crypto Recovery Services about my difficulties and gave all of the necessary paperwork. I was astounded that it took them 12 hours to reclaim my stolen money back. Without a doubt, my USDT assets were successfully recovered from the scam platform, Thank you so much Sir, I strongly recommend Capital Crypto Recover for any of your bitcoin recovery, digital funds recovery, hacking, and cybersecurity concerns. You reach them Call/Text Number +1 (336)390-6684 His Email: [email protected] Contact Telegram: @Capitalcryptorecover Via Contact: [email protected] His website: https://recovercapital.wixsite.com/capital-crypto-rec-1
-
27.11.25 23:48
elizabethrush89
God bless Capital Crypto Recover Services for the marvelous work you did in my life, I have learned the hard way that even the most sensible investors can fall victim to scams. When my USD was stolen, for anyone who has fallen victim to one of the bitcoin binary investment scams that are currently ongoing, I felt betrayal and upset. But then I was reading a post on site when I saw a testimony of Wendy Taylor online who recommended that Capital Crypto Recovery has helped her recover scammed funds within 24 hours. after reaching out to this cyber security firm that was able to help me recover my stolen digital assets and bitcoin. I’m genuinely blown away by their amazing service and professionalism. I never imagined I’d be able to get my money back until I complained to Capital Crypto Recovery Services about my difficulties and gave all of the necessary paperwork. I was astounded that it took them 12 hours to reclaim my stolen money back. Without a doubt, my USDT assets were successfully recovered from the scam platform, Thank you so much Sir, I strongly recommend Capital Crypto Recover for any of your bitcoin recovery, digital funds recovery, hacking, and cybersecurity concerns. You reach them Call/Text Number +1 (336)390-6684 His Email: [email protected] Contact Telegram: @Capitalcryptorecover Via Contact: [email protected] His website: https://recovercapital.wixsite.com/capital-crypto-rec-1
-
28.11.25 00:08
VERONICAFREDDIE809
Earlier this year, I made a mistake that changed everything. I downloaded what I thought was a legitimate trading app I’d found through a Telegram channel. At first, everything looked real until I tried to withdraw. My entire investment vanished into a bot account, and that’s when the truth hit me: I had been scammed. I can’t describe the feeling. It was as if the ground dropped out from under me. I blamed myself. I felt stupid, ashamed, helpless every painful emotion at once. For a while, I couldn’t even talk about it. I thought no one would understand. But then I found someone Agent Jasmine Lopez ([email protected])WhatsApp at +44 736-644-5035. ,She didn’t brush me off or judge me. She took my fear seriously. She followed leads I didn’t even know existed, and identified multiple off-chain indicators and wallet clusters linked to the scammer network, she helped me understand what had truly happened behind the scenes. For the first time since everything fell apart, I felt hope. Hearing that other people students, parents, hardworking people had been targeted the same way made me realize I wasn’t alone. What happened to us wasn’t stupidity. It was a coordinated attack. We were prey in a system built to deceive. And somehow, through all the chaos, Agent Jasmine stepped in and shined a light into the darkest moment of my life. I’m still healing from the experience. It changed me. But it also reminded me that even when you think you’re at the end, sometimes a lifeline appears where you least expect it.
-
 28.11.25 11:15
robertalfred175
28.11.25 11:15
robertalfred175
CRYPTO SCAM RECOVERY SUCCESSFUL – A TESTIMONIAL OF LOST PASSWORD TO YOUR DIGITAL WALLET BACK. My name is Robert Alfred, Am from Australia. I’m sharing my experience in the hope that it helps others who have been victims of crypto scams. A few months ago, I fell victim to a fraudulent crypto investment scheme linked to a broker company. I had invested heavily during a time when Bitcoin prices were rising, thinking it was a good opportunity. Unfortunately, I was scammed out of $120,000 AUD and the broker denied me access to my digital wallet and assets. It was a devastating experience that caused many sleepless nights. Crypto scams are increasingly common and often involve fake trading platforms, phishing attacks, and misleading investment opportunities. In my desperation, a friend from the crypto community recommended Capital Crypto Recovery Service, known for helping victims recover lost or stolen funds. After doing some research and reading multiple positive reviews, I reached out to Capital Crypto Recovery. I provided all the necessary information—wallet addresses, transaction history, and communication logs. Their expert team responded immediately and began investigating. Using advanced blockchain tracking techniques, they were able to trace the stolen Dogecoin, identify the scammer’s wallet, and coordinate with relevant authorities to freeze the funds before they could be moved. Incredibly, within 24 hours, Capital Crypto Recovery successfully recovered the majority of my stolen crypto assets. I was beyond relieved and truly grateful. Their professionalism, transparency, and constant communication throughout the process gave me hope during a very difficult time. If you’ve been a victim of a crypto scam, I highly recommend them with full confidence contacting: 📧 Email: [email protected] 📱 Telegram: @Capitalcryptorecover Contact: [email protected] 📞 Call/Text: +1 (336) 390-6684 🌐 Website: https://recovercapital.wixsite.com/capital-crypto-rec-1
-
28.11.25 11:15
robertalfred175
CRYPTO SCAM RECOVERY SUCCESSFUL – A TESTIMONIAL OF LOST PASSWORD TO YOUR DIGITAL WALLET BACK. My name is Robert Alfred, Am from Australia. I’m sharing my experience in the hope that it helps others who have been victims of crypto scams. A few months ago, I fell victim to a fraudulent crypto investment scheme linked to a broker company. I had invested heavily during a time when Bitcoin prices were rising, thinking it was a good opportunity. Unfortunately, I was scammed out of $120,000 AUD and the broker denied me access to my digital wallet and assets. It was a devastating experience that caused many sleepless nights. Crypto scams are increasingly common and often involve fake trading platforms, phishing attacks, and misleading investment opportunities. In my desperation, a friend from the crypto community recommended Capital Crypto Recovery Service, known for helping victims recover lost or stolen funds. After doing some research and reading multiple positive reviews, I reached out to Capital Crypto Recovery. I provided all the necessary information—wallet addresses, transaction history, and communication logs. Their expert team responded immediately and began investigating. Using advanced blockchain tracking techniques, they were able to trace the stolen Dogecoin, identify the scammer’s wallet, and coordinate with relevant authorities to freeze the funds before they could be moved. Incredibly, within 24 hours, Capital Crypto Recovery successfully recovered the majority of my stolen crypto assets. I was beyond relieved and truly grateful. Their professionalism, transparency, and constant communication throughout the process gave me hope during a very difficult time. If you’ve been a victim of a crypto scam, I highly recommend them with full confidence contacting: 📧 Email: [email protected] 📱 Telegram: @Capitalcryptorecover Contact: [email protected] 📞 Call/Text: +1 (336) 390-6684 🌐 Website: https://recovercapital.wixsite.com/capital-crypto-rec-1
-
28.11.25 11:43
elizabethmadison
My name is Elizabeth Madison currently living in New York. There was a time I felt completely broken. I had trusted a fraudulent bitcoin investment organization, who turned out to be a fraudster. I sent money, believing their sweet words and promises on the interest rate I will get back in return, only to realize later that I’ve been scammed. On the day of withdrawal there was no money in my account. The pain hit deep. I couldn’t sleep, I kept asking myself how I could have been so careless, meanwhile my mom was battling with a stroke and the expenses were too much. For days, I cried and blamed myself. The betrayal, the disappointment and my mom's health issues all of this stress made me want to give up on life. But one day, I decided that sitting in pain wouldn’t solve anything. I picked myself up and chose to fight for what I lost then I came across GREAT WHIP RECOVERY CYBER SERVICES and saw how he helped people recover their funds from online fraud. I emailed all the transactions and paperwork I had with the fraudulent organization and they helped me recover all my lost money in just five days. If you have ever fallen victim to scammers, contact GREAT WHIP RECOVERY CYBER SERVICES to help you recover every penny you have lost. (Text +1(406)2729101) Website https://greatwhiprecoveryc.wixsite.com/greatwhip-site (Email [email protected])
-
28.11.25 11:43
elizabethmadison
My name is Elizabeth Madison currently living in New York. There was a time I felt completely broken. I had trusted a fraudulent bitcoin investment organization, who turned out to be a fraudster. I sent money, believing their sweet words and promises on the interest rate I will get back in return, only to realize later that I’ve been scammed. On the day of withdrawal there was no money in my account. The pain hit deep. I couldn’t sleep, I kept asking myself how I could have been so careless, meanwhile my mom was battling with a stroke and the expenses were too much. For days, I cried and blamed myself. The betrayal, the disappointment and my mom's health issues all of this stress made me want to give up on life. But one day, I decided that sitting in pain wouldn’t solve anything. I picked myself up and chose to fight for what I lost then I came across GREAT WHIP RECOVERY CYBER SERVICES and saw how he helped people recover their funds from online fraud. I emailed all the transactions and paperwork I had with the fraudulent organization and they helped me recover all my lost money in just five days. If you have ever fallen victim to scammers, contact GREAT WHIP RECOVERY CYBER SERVICES to help you recover every penny you have lost. (Text +1(406)2729101) Website https://greatwhiprecoveryc.wixsite.com/greatwhip-site (Email [email protected])
-
29.11.25 12:35
elizabethrush89
God bless Capital Crypto Recover Services for the marvelous work you did in my life, I have learned the hard way that even the most sensible investors can fall victim to scams. When my USD was stolen, for anyone who has fallen victim to one of the bitcoin binary investment scams that are currently ongoing, I felt betrayal and upset. But then I was reading a post on site when I saw a testimony of Wendy Taylor online who recommended that Capital Crypto Recovery has helped her recover scammed funds within 24 hours. after reaching out to this cyber security firm that was able to help me recover my stolen digital assets and bitcoin. I’m genuinely blown away by their amazing service and professionalism. I never imagined I’d be able to get my money back until I complained to Capital Crypto Recovery Services about my difficulties and gave all of the necessary paperwork. I was astounded that it took them 12 hours to reclaim my stolen money back. Without a doubt, my USDT assets were successfully recovered from the scam platform, Thank you so much Sir, I strongly recommend Capital Crypto Recover for any of your bitcoin recovery, digital funds recovery, hacking, and cybersecurity concerns. You reach them Call/Text Number +1 (336)390-6684 His Email: [email protected] Contact Telegram: @Capitalcryptorecover Via Contact: [email protected] His website: https://recovercapital.wixsite.com/capital-crypto-rec-1
-
29.11.25 12:35
elizabethrush89
God bless Capital Crypto Recover Services for the marvelous work you did in my life, I have learned the hard way that even the most sensible investors can fall victim to scams. When my USD was stolen, for anyone who has fallen victim to one of the bitcoin binary investment scams that are currently ongoing, I felt betrayal and upset. But then I was reading a post on site when I saw a testimony of Wendy Taylor online who recommended that Capital Crypto Recovery has helped her recover scammed funds within 24 hours. after reaching out to this cyber security firm that was able to help me recover my stolen digital assets and bitcoin. I’m genuinely blown away by their amazing service and professionalism. I never imagined I’d be able to get my money back until I complained to Capital Crypto Recovery Services about my difficulties and gave all of the necessary paperwork. I was astounded that it took them 12 hours to reclaim my stolen money back. Without a doubt, my USDT assets were successfully recovered from the scam platform, Thank you so much Sir, I strongly recommend Capital Crypto Recover for any of your bitcoin recovery, digital funds recovery, hacking, and cybersecurity concerns. You reach them Call/Text Number +1 (336)390-6684 His Email: [email protected] Contact Telegram: @Capitalcryptorecover Via Contact: [email protected] His website: https://recovercapital.wixsite.com/capital-crypto-rec-1
-
29.11.25 12:35
elizabethrush89
God bless Capital Crypto Recover Services for the marvelous work you did in my life, I have learned the hard way that even the most sensible investors can fall victim to scams. When my USD was stolen, for anyone who has fallen victim to one of the bitcoin binary investment scams that are currently ongoing, I felt betrayal and upset. But then I was reading a post on site when I saw a testimony of Wendy Taylor online who recommended that Capital Crypto Recovery has helped her recover scammed funds within 24 hours. after reaching out to this cyber security firm that was able to help me recover my stolen digital assets and bitcoin. I’m genuinely blown away by their amazing service and professionalism. I never imagined I’d be able to get my money back until I complained to Capital Crypto Recovery Services about my difficulties and gave all of the necessary paperwork. I was astounded that it took them 12 hours to reclaim my stolen money back. Without a doubt, my USDT assets were successfully recovered from the scam platform, Thank you so much Sir, I strongly recommend Capital Crypto Recover for any of your bitcoin recovery, digital funds recovery, hacking, and cybersecurity concerns. You reach them Call/Text Number +1 (336)390-6684 His Email: [email protected] Contact Telegram: @Capitalcryptorecover Via Contact: [email protected] His website: https://recovercapital.wixsite.com/capital-crypto-rec-1
-
30.11.25 20:37
robertalfred175
CRYPTO SCAM RECOVERY SUCCESSFUL – A TESTIMONIAL OF LOST PASSWORD TO YOUR DIGITAL WALLET BACK. My name is Robert Alfred, Am from Australia. I’m sharing my experience in the hope that it helps others who have been victims of crypto scams. A few months ago, I fell victim to a fraudulent crypto investment scheme linked to a broker company. I had invested heavily during a time when Bitcoin prices were rising, thinking it was a good opportunity. Unfortunately, I was scammed out of $120,000 AUD and the broker denied me access to my digital wallet and assets. It was a devastating experience that caused many sleepless nights. Crypto scams are increasingly common and often involve fake trading platforms, phishing attacks, and misleading investment opportunities. In my desperation, a friend from the crypto community recommended Capital Crypto Recovery Service, known for helping victims recover lost or stolen funds. After doing some research and reading multiple positive reviews, I reached out to Capital Crypto Recovery. I provided all the necessary information—wallet addresses, transaction history, and communication logs. Their expert team responded immediately and began investigating. Using advanced blockchain tracking techniques, they were able to trace the stolen Dogecoin, identify the scammer’s wallet, and coordinate with relevant authorities to freeze the funds before they could be moved. Incredibly, within 24 hours, Capital Crypto Recovery successfully recovered the majority of my stolen crypto assets. I was beyond relieved and truly grateful. Their professionalism, transparency, and constant communication throughout the process gave me hope during a very difficult time. If you’ve been a victim of a crypto scam, I highly recommend them with full confidence contacting: 📧 Email: [email protected] 📱 Telegram: @Capitalcryptorecover Contact: [email protected] 📞 Call/Text: +1 (336) 390-6684 🌐 Website: https://recovercapital.wixsite.com/capital-crypto-rec-1
-
 01.12.25 12:27
Thomas Muller
01.12.25 12:27
Thomas Muller
YOU CAN REACH OUT TO GREAT WHIP RECOVERY CYBER SERVICES FOR HELP TO RECOVER YOUR STOLEN BTC OR ETH BACK WHATSAPP +1(208)713-0697 I once fell victim to online investment scheme that cost me a devastating €254,000. I’m Thomas Muller from Berlin, Germany. The person I trusted turned out to be a fraud, and the moment I realized I’d been deceived, my entire world stopped. I immediately began searching for legitimate ways to recover my funds and hold the scammer accountable. During my search, I came across several testimonies of how Great Whip Recovery Cyber Services helped some people recover money they lost to cyber fraud, I contacted Great Whip Recovery Cyber Service team and provided all the evidence I had. Within about 36 hours, the experts traced the digital trail left by the fraudster, the individual was eventually tracked down and I recovered all my money back. You can contact them with, website https://greatwhiprecoveryc.wixsite.com/greatwhip-site text +1(406)2729101 email [email protected]
-
01.12.25 12:27
Thomas Muller
YOU CAN REACH OUT TO GREAT WHIP RECOVERY CYBER SERVICES FOR HELP TO RECOVER YOUR STOLEN BTC OR ETH BACK WHATSAPP +1(208)713-0697 I once fell victim to online investment scheme that cost me a devastating €254,000. I’m Thomas Muller from Berlin, Germany. The person I trusted turned out to be a fraud, and the moment I realized I’d been deceived, my entire world stopped. I immediately began searching for legitimate ways to recover my funds and hold the scammer accountable. During my search, I came across several testimonies of how Great Whip Recovery Cyber Services helped some people recover money they lost to cyber fraud, I contacted Great Whip Recovery Cyber Service team and provided all the evidence I had. Within about 36 hours, the experts traced the digital trail left by the fraudster, the individual was eventually tracked down and I recovered all my money back. You can contact them with, website https://greatwhiprecoveryc.wixsite.com/greatwhip-site text +1(406)2729101 email [email protected]
-
01.12.25 23:45
michaeldavenport238
I was recently scammed out of $53,000 by a fraudulent Bitcoin investment scheme, which added significant stress to my already difficult health issues, as I was also facing cancer surgery expenses. Desperate to recover my funds, I spent hours researching and consulting other victims, which led me to discover the excellent reputation of Capital Crypto Recover, I came across a Google post It was only after spending many hours researching and asking other victims for advice that I discovered Capital Crypto Recovery’s stellar reputation. I decided to contact them because of their successful recovery record and encouraging client testimonials. I had no idea that this would be the pivotal moment in my fight against cryptocurrency theft. Thanks to their expert team, I was able to recover my lost cryptocurrency back. The process was intricate, but Capital Crypto Recovery's commitment to utilizing the latest technology ensured a successful outcome. I highly recommend their services to anyone who has fallen victim to cryptocurrency fraud. For assistance contact [email protected] and on Telegram OR Call Number +1 (336)390-6684 via email: [email protected] you can visit his website: https://recovercapital.wixsite.com/capital-crypto-rec-1
-
01.12.25 23:45
michaeldavenport238
I was recently scammed out of $53,000 by a fraudulent Bitcoin investment scheme, which added significant stress to my already difficult health issues, as I was also facing cancer surgery expenses. Desperate to recover my funds, I spent hours researching and consulting other victims, which led me to discover the excellent reputation of Capital Crypto Recover, I came across a Google post It was only after spending many hours researching and asking other victims for advice that I discovered Capital Crypto Recovery’s stellar reputation. I decided to contact them because of their successful recovery record and encouraging client testimonials. I had no idea that this would be the pivotal moment in my fight against cryptocurrency theft. Thanks to their expert team, I was able to recover my lost cryptocurrency back. The process was intricate, but Capital Crypto Recovery's commitment to utilizing the latest technology ensured a successful outcome. I highly recommend their services to anyone who has fallen victim to cryptocurrency fraud. For assistance contact [email protected] and on Telegram OR Call Number +1 (336)390-6684 via email: [email protected] you can visit his website: https://recovercapital.wixsite.com/capital-crypto-rec-1
-
02.12.25 02:21
donald121
In 2025 alone, hackers stole over $1.5 billion in digital assets from users worldwide. That's a wake-up call for anyone holding crypto. Theft hits hard because once funds move, they're tough to get back. Common ways it happens include phishing emails that trick you into giving up keys, big exchange breaches, or malware sneaking into your wallet. Marie guide walks you through steps to recover stolen cryptocurrency. You'll learn quick actions to stop more loss, how to trace funds, and ways to fight back legally. Plus, tips to avoid this mess next time. reach her (infocyberrecoveryinc@gmail com and whatsapp:+1 7127594675)
-
02.12.25 15:05
Matt Kegan
Reach out to SolidBlock Forensics if you want to get back your coins from fake crypto investment or your wallet was compromised and all your coins gone. SolidBlock Forensics provide deep ethical analysis and investigation that enables them to trace these schemes, and recover all your funds. Their services are professional and reliable.
-
03.12.25 09:22
tyrelldavis1
I still recall the day I fell victim to an online scam, losing a substantial amount of money to a cunning fraudster. The feeling of helplessness and despair that followed was overwhelming, and I thought I had lost all hope of ever recovering my stolen funds. However, after months of searching for a solution, I stumbled upon a beacon of hope - GRAYWARE TECH SERVICE, a highly reputable and exceptionally skilled investigative and recovery firm. Their team of expert cybersecurity professionals specializes in tracking and retrieving money lost to internet fraud, and I was impressed by their unwavering dedication to helping victims like me. With their extensive knowledge and cutting-edge technology, they were able to navigate the complex world of online finance and identify the culprits behind my loss. What struck me most about GRAYWARE TECH SERVICE was their unparalleled expertise and exceptional customer service. They took the time to understand my situation, provided me with regular updates, and kept me informed throughout the entire recovery process. Their transparency and professionalism were truly reassuring, and I felt confident that I had finally found a reliable partner to help me recover my stolen money. Thanks to GRAYWARE TECH SERVICE, I was able to recover a significant portion of my lost funds, and I am forever grateful for their assistance. Their success in retrieving my money not only restored my financial stability but also restored my faith in the ability of authorities to combat online fraud. If you have fallen victim to internet scams, I highly recommend reaching out to GRAYWARE TECH SERVICE - their expertise and dedication to recovering stolen funds are unparalleled, and they may be your only hope for retrieving what is rightfully yours. You can reach them on whatsapp+18582759508 web at ( https://graywaretechservice.com/ ) also on Mail: ([email protected]
-
03.12.25 21:01
VERONICAFREDDIE809
Earlier this year, I made a mistake that changed everything. I downloaded what I thought was a legitimate trading app I’d found through a Telegram channel. At first, everything looked real until I tried to withdraw. My entire investment vanished into a bot account, and that’s when the truth hit me: I had been scammed. I can’t describe the feeling. It was as if the ground dropped out from under me. I blamed myself. I felt stupid, ashamed, helpless every painful emotion at once. For a while, I couldn’t even talk about it. I thought no one would understand. But then I found someone Agent Jasmine Lopez ([email protected]) ,She didn’t brush me off or judge me. She took my fear seriously. She followed leads I didn’t even know existed, and identified multiple off-chain indicators and wallet clusters linked to the scammer network, she helped me understand what had truly happened behind the scenes. For the first time since everything fell apart, I felt hope. Hearing that other people students, parents, hardworking people had been targeted the same way made me realize I wasn’t alone. What happened to us wasn’t stupidity. It was a coordinated attack. We were prey in a system built to deceive. And somehow, through all the chaos, Agent Jasmine stepped in and shined a light into the darkest moment of my life. I’m still healing from the experience. It changed me. But it also reminded me that even when you think you’re at the end, sometimes a lifeline appears where you least expect it. Contact her at [email protected] WhatsApp at +44 736-644-5035.
-
03.12.25 22:17
Tonerdomark
I lost $300,000 in USDC to a phishing scam. Scammers tricked me with a fake wallet link. They drained my account fast. I felt hopeless. No way to get it back. Then Sylvester stepped in. His skills traced the funds. He recovered every bit. USDC is a stablecoin tied to the dollar. Phishing scams hit hard in crypto. They fool you with urgent emails or sites. Billions vanish each year this way. Sylvester knows blockchain tracks. He used tools to follow the trail. I got my money back in weeks. Skills like his turn loss to win. Don't wait if scammed. Contact Mr. Sylvester now. Email: yt7cracker@gmail. com. WhatsApp only: + 1 512 577 7957 or + 44 7428 662701. He helped me. He can help you.
-
04.12.25 01:37
michaeldavenport238
I was recently scammed out of $53,000 by a fraudulent Bitcoin investment scheme, which added significant stress to my already difficult health issues, as I was also facing cancer surgery expenses. Desperate to recover my funds, I spent hours researching and consulting other victims, which led me to discover the excellent reputation of Capital Crypto Recover, I came across a Google post It was only after spending many hours researching and asking other victims for advice that I discovered Capital Crypto Recovery’s stellar reputation. I decided to contact them because of their successful recovery record and encouraging client testimonials. I had no idea that this would be the pivotal moment in my fight against cryptocurrency theft. Thanks to their expert team, I was able to recover my lost cryptocurrency back. The process was intricate, but Capital Crypto Recovery's commitment to utilizing the latest technology ensured a successful outcome. I highly recommend their services to anyone who has fallen victim to cryptocurrency fraud. For assistance contact [email protected] and on Telegram OR Call Number +1 (336)390-6684 via email: [email protected] you can visit his website: https://recovercapital.wixsite.com/capital-crypto-rec-1
-
04.12.25 01:37
michaeldavenport238
I was recently scammed out of $53,000 by a fraudulent Bitcoin investment scheme, which added significant stress to my already difficult health issues, as I was also facing cancer surgery expenses. Desperate to recover my funds, I spent hours researching and consulting other victims, which led me to discover the excellent reputation of Capital Crypto Recover, I came across a Google post It was only after spending many hours researching and asking other victims for advice that I discovered Capital Crypto Recovery’s stellar reputation. I decided to contact them because of their successful recovery record and encouraging client testimonials. I had no idea that this would be the pivotal moment in my fight against cryptocurrency theft. Thanks to their expert team, I was able to recover my lost cryptocurrency back. The process was intricate, but Capital Crypto Recovery's commitment to utilizing the latest technology ensured a successful outcome. I highly recommend their services to anyone who has fallen victim to cryptocurrency fraud. For assistance contact [email protected] and on Telegram OR Call Number +1 (336)390-6684 via email: [email protected] you can visit his website: https://recovercapital.wixsite.com/capital-crypto-rec-1
-
04.12.25 04:35
Tonerdomark
I lost $300,000 in USDC to a phishing scam. Scammers tricked me with a fake wallet link. They drained my account fast. I felt hopeless. No way to get it back. Then Sylvester stepped in. His skills traced the funds. He recovered every bit. USDC is a stablecoin tied to the dollar. Phishing scams hit hard in crypto. They fool you with urgent emails or sites. Billions vanish each year this way. Sylvester knows blockchain tracks. He used tools to follow the trail. I got my money back in weeks. Skills like his turn loss to win. Don't wait if scammed. Contact Mr. Sylvester now. Email: [email protected]. WhatsApp only: + 1 512 577 7957 or + 44 7428 662701. He helped me. He can help you.
-
04.12.25 10:32
Tonerdomark
I lost $300,000 in USDC to a phishing scam. Scammers tricked me with a fake wallet link. They drained my account fast. I felt hopeless. No way to get it back. Then Sylvester stepped in. His skills traced the funds. He recovered every bit. USDC is a stablecoin tied to the dollar. Phishing scams hit hard in crypto. They fool you with urgent emails or sites. Billions vanish each year this way. Sylvester knows blockchain tracks. He used tools to follow the trail. I got my money back in weeks. Skills like his turn loss to win. Don't wait if scammed. Contact Mr. Sylvester now. Email: [email protected]. WhatsApp only: + 1 512 577 7957 or + 44 7428 662701. He helped me. He can help you.
-
 04.12.25 18:25
smithhazael
04.12.25 18:25
smithhazael
Hire Proficient Expert Consultant For any form of lost crypto "A man in Indonesia tragically took his own life after losing his family's savings to a scam. The shame and blame were too much to bear. It's heartbreaking to think he might still be alive if he knew help existed. "PROFICIENT EXPERT CONSULTANTS, I worked alongside PROFICIENT EXPERT CONSULTANTS when I lost my funds to an investment platform on Telegram. PROFICIENT EXPERT CONSULTANTS did a praiseworthy job, tracked and successfully recovered all my lost funds a total of $770,000 within 48hours after contacting them, with their verse experience in recovery issues and top tier skills they were able to transfer back all my funds into my account, to top it up I had full access to my account and immediately converted it to cash, they handled my case with professionalism and empathy and successfully recovered all my lost funds, with so many good reviews about PROFICIENT EXPERT CONSULTANTS, I’m glad I followed my instincts after reading all the reviews and I was able to recovery everything I thought I had lost, don’t commit suicide if in any case you are caught in the same situation, contact: Proficientexpert@consultant. com Telegram: @ PROFICIENTEXPERT, the reliable experts in recovery.
-
04.12.25 21:45
elizabethrush89
God bless Capital Crypto Recover Services for the marvelous work you did in my life, I have learned the hard way that even the most sensible investors can fall victim to scams. When my USD was stolen, for anyone who has fallen victim to one of the bitcoin binary investment scams that are currently ongoing, I felt betrayal and upset. But then I was reading a post on site when I saw a testimony of Wendy Taylor online who recommended that Capital Crypto Recovery has helped her recover scammed funds within 24 hours. after reaching out to this cyber security firm that was able to help me recover my stolen digital assets and bitcoin. I’m genuinely blown away by their amazing service and professionalism. I never imagined I’d be able to get my money back until I complained to Capital Crypto Recovery Services about my difficulties and gave all of the necessary paperwork. I was astounded that it took them 12 hours to reclaim my stolen money back. Without a doubt, my USDT assets were successfully recovered from the scam platform, Thank you so much Sir, I strongly recommend Capital Crypto Recover for any of your bitcoin recovery, digital funds recovery, hacking, and cybersecurity concerns. You reach them Call/Text Number +1 (336)390-6684 His Email: [email protected] Contact Telegram: @Capitalcryptorecover Via Contact: [email protected] His website: https://recovercapital.wixsite.com/capital-crypto-rec-1
-
04.12.25 21:45
elizabethrush89
God bless Capital Crypto Recover Services for the marvelous work you did in my life, I have learned the hard way that even the most sensible investors can fall victim to scams. When my USD was stolen, for anyone who has fallen victim to one of the bitcoin binary investment scams that are currently ongoing, I felt betrayal and upset. But then I was reading a post on site when I saw a testimony of Wendy Taylor online who recommended that Capital Crypto Recovery has helped her recover scammed funds within 24 hours. after reaching out to this cyber security firm that was able to help me recover my stolen digital assets and bitcoin. I’m genuinely blown away by their amazing service and professionalism. I never imagined I’d be able to get my money back until I complained to Capital Crypto Recovery Services about my difficulties and gave all of the necessary paperwork. I was astounded that it took them 12 hours to reclaim my stolen money back. Without a doubt, my USDT assets were successfully recovered from the scam platform, Thank you so much Sir, I strongly recommend Capital Crypto Recover for any of your bitcoin recovery, digital funds recovery, hacking, and cybersecurity concerns. You reach them Call/Text Number +1 (336)390-6684 His Email: [email protected] Contact Telegram: @Capitalcryptorecover Via Contact: [email protected] His website: https://recovercapital.wixsite.com/capital-crypto-rec-1
-
 05.12.25 08:35
into11
05.12.25 08:35
into11
The digital world of cryptocurrency offers big chances, but it also hides tricky scams. Losing your crypto to fraud feels awful. It can leave you feeling lost and violated. This guide tells you what to do right away if a crypto scam has hit you. These steps can help you get funds back or stop more trouble. Knowing what to do fast can change everything,reach marie ([email protected] and whatsapp:+1 7127594675)
-
05.12.25 08:48
Tonerdomark
SYLVESTER BRYANT WAS A PROFESSIONAL/ RELIABLE HACKER AND HIGHLY RECOMMENDED I’m very excited to speak about him as a Bitcoin Recovery agent, this cyber security company was able to assist me in recovering my stolen funds in cryptocurrency. I’m truly amazed by their excellent service and professional work. I never thought I could get back my funds until I approached them with my problems and provided all the necessary information. It took them time to recover my funds and I was amazed. Without any doubt, I highly recommend Sylvester for your BITCOIN, USDC, USDT, ETH Recovery, for all Cryptocurrency recovery, digital funds recovery, hacking Related issues, contact Sylvester Bryant professional services waapp only= +1 512 577 7957 or + 44 7428 662701 EMAIL = [email protected]
-
06.12.25 01:44
Tonerdomark
SYLVESTER BRYANT WAS A PROFESSIONAL/ RELIABLE HACKER AND HIGHLY RECOMMENDED I’m very excited to speak about him as a Bitcoin Recovery agent, this cyber security company was able to assist me in recovering my stolen funds in cryptocurrency. I’m truly amazed by their excellent service and professional work. I never thought I could get back my funds until I approached them with my problems and provided all the necessary information. It took them time to recover my funds and I was amazed. Without any doubt, I highly recommend Sylvester for your BITCOIN, USDC, USDT, ETH Recovery, for all Cryptocurrency recovery, digital funds recovery, hacking Related issues, contact Sylvester Bryant professional services waapp only= +1 512 577 7957 or + 44 7428 662701 EMAIL = [email protected]
-
06.12.25 01:48
Tonerdomark
SYLVESTER BRYANT WAS A PROFESSIONAL/ RELIABLE HACKER AND HIGHLY RECOMMENDED I’m very excited to speak about him as a Bitcoin Recovery agent, this cyber security company was able to assist me in recovering my stolen funds in cryptocurrency. I’m truly amazed by their excellent service and professional work. I never thought I could get back my funds until I approached them with my problems and provided all the necessary information. It took them time to recover my funds and I was amazed. Without any doubt, I highly recommend Sylvester for your BITCOIN, USDC, USDT, ETH Recovery, for all Cryptocurrency recovery, digital funds recovery, hacking Related issues, contact Sylvester Bryant professional services waapp only= +1 512 577 7957 or + 44 7428 662701 EMAIL = [email protected]
-
06.12.25 10:36
Thomas Muller
YOU CAN REACH OUT TO GREAT WHIP RECOVERY CYBER SERVICES FOR HELP TO RECOVER YOUR STOLEN BTC OR ETH BACK WHATSAPP +1(208)713-0697 I once fell victim to online investment scheme that cost me a devastating €254,000. I’m Thomas Muller from Berlin, Germany. The person I trusted turned out to be a fraud, and the moment I realized I’d been deceived, my entire world stopped. I immediately began searching for legitimate ways to recover my funds and hold the scammer accountable. During my search, I came across several testimonies of how Great Whip Recovery Cyber Services helped some people recover money they lost to cyber fraud, I contacted Great Whip Recovery Cyber Service team and provided all the evidence I had. Within about 36 hours, the experts traced the digital trail left by the fraudster, the individual was eventually tracked down and I recovered all my money back. You can contact them with, website https://greatwhiprecoveryc.wixsite.com/greatwhip-site text +1(406)2729101 email [email protected]
-
06.12.25 10:36
Thomas Muller
YOU CAN REACH OUT TO GREAT WHIP RECOVERY CYBER SERVICES FOR HELP TO RECOVER YOUR STOLEN BTC OR ETH BACK WHATSAPP +1(208)713-0697 I once fell victim to online investment scheme that cost me a devastating €254,000. I’m Thomas Muller from Berlin, Germany. The person I trusted turned out to be a fraud, and the moment I realized I’d been deceived, my entire world stopped. I immediately began searching for legitimate ways to recover my funds and hold the scammer accountable. During my search, I came across several testimonies of how Great Whip Recovery Cyber Services helped some people recover money they lost to cyber fraud, I contacted Great Whip Recovery Cyber Service team and provided all the evidence I had. Within about 36 hours, the experts traced the digital trail left by the fraudster, the individual was eventually tracked down and I recovered all my money back. You can contact them with, website https://greatwhiprecoveryc.wixsite.com/greatwhip-site text +1(406)2729101 email [email protected]
-
06.12.25 10:39
michaeldavenport238
I was recently scammed out of $53,000 by a fraudulent Bitcoin investment scheme, which added significant stress to my already difficult health issues, as I was also facing cancer surgery expenses. Desperate to recover my funds, I spent hours researching and consulting other victims, which led me to discover the excellent reputation of Capital Crypto Recover, I came across a Google post It was only after spending many hours researching and asking other victims for advice that I discovered Capital Crypto Recovery’s stellar reputation. I decided to contact them because of their successful recovery record and encouraging client testimonials. I had no idea that this would be the pivotal moment in my fight against cryptocurrency theft. Thanks to their expert team, I was able to recover my lost cryptocurrency back. The process was intricate, but Capital Crypto Recovery's commitment to utilizing the latest technology ensured a successful outcome. I highly recommend their services to anyone who has fallen victim to cryptocurrency fraud. For assistance contact [email protected] and on Telegram OR Call Number +1 (336)390-6684 via email: [email protected] you can visit his website: https://recovercapital.wixsite.com/capital-crypto-rec-1
-
06.12.25 10:42
michaeldavenport238
I was recently scammed out of $53,000 by a fraudulent Bitcoin investment scheme, which added significant stress to my already difficult health issues, as I was also facing cancer surgery expenses. Desperate to recover my funds, I spent hours researching and consulting other victims, which led me to discover the excellent reputation of Capital Crypto Recover, I came across a Google post It was only after spending many hours researching and asking other victims for advice that I discovered Capital Crypto Recovery’s stellar reputation. I decided to contact them because of their successful recovery record and encouraging client testimonials. I had no idea that this would be the pivotal moment in my fight against cryptocurrency theft. Thanks to their expert team, I was able to recover my lost cryptocurrency back. The process was intricate, but Capital Crypto Recovery's commitment to utilizing the latest technology ensured a successful outcome. I highly recommend their services to anyone who has fallen victim to cryptocurrency fraud. For assistance contact [email protected] and on Telegram OR Call Number +1 (336)390-6684 via email: [email protected] you can visit his website: https://recovercapital.wixsite.com/capital-crypto-rec-1
-
07.12.25 08:43
Tonerdomark
SYLVESTER BRYANT WAS A PROFESSIONAL/ RELIABLE HACKER AND HIGHLY RECOMMENDED I’m very excited to speak about him as a Bitcoin Recovery agent, this cyber security company was able to assist me in recovering my stolen funds in cryptocurrency. I’m truly amazed by their excellent service and professional work. I never thought I could get back my funds until I approached them with my problems and provided all the necessary information. It took them time to recover my funds and I was amazed. Without any doubt, I highly recommend Sylvester for your BITCOIN, USDC, USDT, ETH Recovery, for all Cryptocurrency recovery, digital funds recovery, hacking Related issues, contact Sylvester Bryant professional services waapp only= +1 512 577 7957 or + 44 7428 662701 EMAIL = [email protected]
-
 08.12.25 02:17
liam
08.12.25 02:17
liam
I recently fell a victim of cryptocurrency investment and mining scam, I lost almost all my life savings to BTC scammers. I almost gave up because the amount of crypto I lost was too much. So I spoke to a friend who told me about ANTHONYDAVIESTECH company. I Contacted them through their email and i provided them with the necessary information they requested from me and they told me to be patient and wait to see the outcome of their job. I was shocked after two days my Bitcoin was returned to my Wallet. All thanks to them for their genius work. I Contacted them via Email: anthonydaviestech @ gmail . com all thanks to my friend who saved my life
-
08.12.25 09:07
Tonerdomark
SYLVESTER BRYANT WAS A PROFESSIONAL/ RELIABLE HACKER AND HIGHLY RECOMMENDED I’m very excited to speak about him as a Bitcoin Recovery agent, this cyber security company was able to assist me in recovering my stolen funds in cryptocurrency. I’m truly amazed by their excellent service and professional work. I never thought I could get back my funds until I approached them with my problems and provided all the necessary information. It took them time to recover my funds and I was amazed. Without any doubt, I highly recommend Sylvester for your BITCOIN, USDC, USDT, ETH Recovery, for all Cryptocurrency recovery, digital funds recovery, hacking Related issues, contact Sylvester Bryant professional services waapp only= +1 512 577 7957 or + 44 7428 662701 EMAIL = [email protected]
-
09.12.25 00:18
swanky
For a long time, I had heard tales of individuals striking it rich through cryptocurrency investments, but I had little knowledge of how the system operated. The potential for financial gain piqued my interest, and I decided to dive in and invest. To help me navigate this complex landscape, I joined a group of online traders who promised to guide me through the investment process. Their confidence and expertise made me feel reassured about my decision.After spending some time learning from them and observing their trading strategies, I felt compelled to invest a substantial amount of money to which i lost, now in search of recovering my funds i got referred to anthonydavies on telegram a funds recovery specialist with his team help i was able to get back $300000 of my usdc back. you can reach him via anthonydaviestech AT gmail dot com
-
09.12.25 01:01
Tonerdomark
SYLVESTER BRYANT WAS A PROFESSIONAL/ RELIABLE HACKER AND HIGHLY RECOMMENDED I’m very excited to speak about him as a Bitcoin Recovery agent, this cyber security company was able to assist me in recovering my stolen funds in cryptocurrency. I’m truly amazed by their excellent service and professional work. I never thought I could get back my funds until I approached them with my problems and provided all the necessary information. It took them time to recover my funds and I was amazed. Without any doubt, I highly recommend Sylvester for your BITCOIN, USDC, USDT, ETH Recovery, for all Cryptocurrency recovery, digital funds recovery, hacking Related issues, contact Sylvester Bryant professional services waapp only= +1 512 577 7957 or + 44 7428 662701 EMAIL = Yt7CRACKER@gmail. com
-
09.12.25 05:44
swanky
For a long time, I had heard tales of individuals striking it rich through cryptocurrency investments, but I had little knowledge of how the system operated. The potential for financial gain piqued my interest, and I decided to dive in and invest. To help me navigate this complex landscape, I joined a group of online traders who promised to guide me through the investment process. Their confidence and expertise made me feel reassured about my decision.After spending some time learning from them and observing their trading strategies, I felt compelled to invest a substantial amount of money to which i lost, now in search of recovering my funds i got referred to anthonydavies on telegram a funds recovery specialist with his team help i was able to get back $300000 of my usdc back. you can reach him via anthonydaviestech AT gmail dot com
-
09.12.25 10:24
lane3215
It is distressing to lose USDT to a bitcoin wallet hack. Although challenging, recovering stolen USDT is feasible. Your chances increase if you move swiftly and strategically. Marie can help you with reporting the theft, recovering USDT, and taking immediate action. You can reach her via mail at [email protected], WhatsApp at +1 7127594675.
-
09.12.25 10:25
lane3215
It is distressing to lose USDT to a bitcoin wallet hack. Although challenging, recovering stolen USDT is feasible. Your chances increase if you move swiftly and strategically. Marie can help you with reporting the theft, recovering USDT, and taking immediate action. You can reach her via mail at [email protected], WhatsApp at +1 7127594675.
-
09.12.25 14:16
Matt Kegan
Grateful i came across SolidBlock Forensics. After investing in crypto trade and couldn't make withdrawals, it dawned on me something was wrong. They kept on asking for taxes, fees for maintenance, and more money for admin reasons. But being represented by SolidBlock Forensics, i was able to file reports, and finally, received all my investments with returns. Its great to know we have professionals that handle such issues and get the job done.
-
12.12.25 22:38
swanky
After reading some reviews on how [anthonydaviestech AT gmail dot (c om) helps people recover money and Cryptocurrencies lost to scammers, I decided to contact him to help me recover mine which I lost in february 2025. To my surprise he was able to trace the USDT from the first wallet to all the wallets it has been sent to. He moved them out of those wallets and returned them back to mine and even added extra to me, it felt like magic.
-
 13.12.25 08:22
Natasha Williams
13.12.25 08:22
Natasha Williams
I am Natasha Williams from Dallas. I want to share my testimony to encourage anyone who has ever fallen victim to a scam or fraud. Some time ago, I was defrauded by some fraudulent cryptocurrency investment organization online, I was a victim and I lost a huge amount of money, $382,000. I felt angry, disappointed and helpless but I refused to give up and stay calm. I came across this agency, GREAT WHIP RECOVERY CYBER SERVICES.. who helped people recover their money from scammers and the testimonies I saw were quite amazing. And I decided to contact them. I gathered every piece of evidence, chats, receipts, account details, and messages and reported the case to the agency, GREAT WHIP RECOVERY CYBER SERVICES. After 73hours of follow up and not losing faith, the fraudster was traced and held accountable and I recovered all my money back. I highly recommend, GREAT WHIP RECOVERY CYBER SERVICES agency if you have ever fallen victim to scammers, you can contact them. Website: https://greatwhiprecoveryc.wixsite.com/greatwhip-site email: [email protected] Call Line: +1(406)2729101
-
13.12.25 08:23
Natasha Williams
I am Natasha Williams from Dallas. I want to share my testimony to encourage anyone who has ever fallen victim to a scam or fraud. Some time ago, I was defrauded by some fraudulent cryptocurrency investment organization online, I was a victim and I lost a huge amount of money, $382,000. I felt angry, disappointed and helpless but I refused to give up and stay calm. I came across this agency, GREAT WHIP RECOVERY CYBER SERVICES.. who helped people recover their money from scammers and the testimonies I saw were quite amazing. And I decided to contact them. I gathered every piece of evidence, chats, receipts, account details, and messages and reported the case to the agency, GREAT WHIP RECOVERY CYBER SERVICES. After 73hours of follow up and not losing faith, the fraudster was traced and held accountable and I recovered all my money back. I highly recommend, GREAT WHIP RECOVERY CYBER SERVICES agency if you have ever fallen victim to scammers, you can contact them. Website: https://greatwhiprecoveryc.wixsite.com/greatwhip-site email: [email protected] Call Line: +1(406)2729101
-
13.12.25 08:28
Natasha Williams
I am Natasha Williams from Dallas. I want to share my testimony to encourage anyone who has ever fallen victim to a scam or fraud. Some time ago, I was defrauded by some fraudulent cryptocurrency investment organization online, I was a victim and I lost a huge amount of money, $382,000. I felt angry, disappointed and helpless but I refused to give up and stay calm. I came across this agency, GREAT WHIP RECOVERY CYBER SERVICES.. who helped people recover their money from scammers and the testimonies I saw were quite amazing. And I decided to contact them. I gathered every piece of evidence, chats, receipts, account details, and messages and reported the case to the agency, GREAT WHIP RECOVERY CYBER SERVICES. After 73hours of follow up and not losing faith, the fraudster was traced and held accountable and I recovered all my money back. I highly recommend, GREAT WHIP RECOVERY CYBER SERVICES agency if you have ever fallen victim to scammers, you can contact them. Website: https://greatwhiprecoveryc.wixsite.com/greatwhip-site email: [email protected] Call Line: +1(406)2729101
-
 13.12.25 15:29
Anthonymorphy30
13.12.25 15:29
Anthonymorphy30
⬛️ ARE YOU SEEKING TO RECOVER YOUR LOST FUNDS FROM INVESTMENT/TRADING SCAM OR ROMANCE SCAM??? OR YOU NEED LEGIT HACKING SERVICES SUCH AS PHONE HACK, WEBSITE HACK AND MORE????? TAKE YOUR TIME TO READ ⬛️ ⬛️ We have received numerous complaints of fraud associated with Romance Scam, websites that offers opportunities for Capital Investments, bitcoin investments and Trading on an Internet-based trading platforms. Most Of theese complaints falls into these theee categories: 1. 🔘Refusal to credit customers accounts or reimburse funds to customers: These complaints typically involves customers who have deposited money into their trading or investment account and eventually got deprived from withdrawing their capital and profits by the trading platforms. 2. 🔘Manipulation of software to generate losing trades: These complaints alleged that the Internet-based Investment and trading platforms manipulate the trading software to distort the Trading prices and payouts in order to ensure that the trade results in a Loss. 3. 🔘 Romance Scam where a scammer pretends to have romantic interest in someone to gain their trust—and then uses that trust to steal money or personal information. ⬛️ Most people have lost their hard earned money through these types of Scams but don’t know how to get a Legitimate Funds Recovery Expert. Truth be told, the only Specialists that is capable of retrieving your lost funds to these scams are Team of professional hackers and cyber forensic experts and this is where FUNDS RETRIEVAL PANEL comes in. FUNDS RETRIEVAL PANEL is an amalgamation of top notch Hackers, Cyber forensic Experts, Software Engineers and Backend Gurus who are dedicated to helping victims retrieve their Lost funds from online scams and frauds. We are the Leading Funds Recovery Expert who know various Retrieval Techniques and Strategies that suits different scenarios of Scam. With years of experience in the financial and tech sectors, we are the trusted solution for individuals looking to recover lost money. CONTACT US NOW to schedule your free consultation and start the process of recovering your funds. 🌍 www.fundsretrievalpanel.com 🌍 📩 [email protected]✉️ ☑️ We Also have a segregated Department that focuses on other LEGIT HACKING SERVICES SUCH AS: ▪️ PHONE HACKING & CLONING : very useful for getting evidence from someone else’s phone by gaining full access to all they do on their phones. ▪️ WEBSITE AND DATABASE HACKING 💻 ▪️ SOCIAL MEDIA ACCOUNTS HACKING 📱 ▪️LOCATION TRACKING 📌 CONTACT: 📩 [email protected]
-
13.12.25 18:52
James Robert
I am James Robert from Chicago. Few months ago, I fell victim to an online Bitcoin investment scheme that promised high returns within a short period. At first, everything seemed legitimate, their website looked professional, and the people behind it were very convincing. I invested a significant amount of money about $440,000 with the way they talk to me into investing on their bitcoin platform. Two months later I realized that it was a scam when I could no longer have access to my account and couldn’t withdraw my money. At first, I lost hope that I wouldn't be able to get my money back, I cried and was angry at how I even fell victim to a scam. For days after doing some research and seeking professional help online, I came across GREAT WHIP RECOVERY CYBER SERVICES and saw how they have helped people recover their money back from scammers. I reported the case immediately to them and gather every transaction detail, documentation and sent it to them. Today, I’m very happy because the GREAT WHIP RECOVERY CYBER SERVICES help me recover all my money I was scammed. You can contact GREAT WHIP RECOVERY CYBER SERVICES if you have ever fallen victim to scam. Email: [email protected] or Website https://greatwhiprecoveryc.wixsite.com/greatwhip-site or Call +1(406)2729101
-
13.12.25 18:54
James Robert
I am James Robert from Chicago. Few months ago, I fell victim to an online Bitcoin investment scheme that promised high returns within a short period. At first, everything seemed legitimate, their website looked professional, and the people behind it were very convincing. I invested a significant amount of money about $440,000 with the way they talk to me into investing on their bitcoin platform. Two months later I realized that it was a scam when I could no longer have access to my account and couldn’t withdraw my money. At first, I lost hope that I wouldn't be able to get my money back, I cried and was angry at how I even fell victim to a scam. For days after doing some research and seeking professional help online, I came across GREAT WHIP RECOVERY CYBER SERVICES and saw how they have helped people recover their money back from scammers. I reported the case immediately to them and gather every transaction detail, documentation and sent it to them. Today, I’m very happy because the GREAT WHIP RECOVERY CYBER SERVICES help me recover all my money I was scammed. You can contact GREAT WHIP RECOVERY CYBER SERVICES if you have ever fallen victim to scam. Email: [email protected] or Website https://greatwhiprecoveryc.wixsite.com/greatwhip-site or Call +1(406)2729101
-
18.12.25 12:12
Anthony Irvin
I forgot my password 🔑 -- But they helped me recover my entire wallet. Successful Brute-Force Hack... On January 16, 2023, INTELLIGENCE CYBER WIZARD successfully hacked my Langerhans.DAT Android DOGECOIN wallet to recover the lost/forgotten spending PIN, necessary for spending funds. It took them only three (3) days to complete the task. It turned out that the spending PIN was only ten (10) digits long, which I had mistakenly believed to be twelve. Once Intelligence Cyber Wizard discovered and recited the full ten-digit PIN to me, based on "clues" I had given them and that only I knew, it reminded me a bit of when I set up the PIN back in 2015. In my case, I made the mistake of not writing it down. The wallet file in this case contained a little over 10.5 million DOGECOINs installed on it, spread across a total of 15 DOGE public wallet addresses and their corresponding private keys. When I acquired the 10.5 million coins in 2015, the total cost to me was only around $1,500, based on the current face value of DOGE at the time, which was approximately $0.0001 per coin. The wallet file had been inaccessible to me since December 27, 2015, after I realized I had forgotten my spending PIN. Before finding Intelligence Cyber Wizard, I had had several other encounters with people who were unsuccessful in recovering the wallet's spending PIN. So, as it turned out, I actually ended up much better off financially because I had forgotten my spending PIN. Had I not forgotten, I would have traded or sold the 10.5 million coins in question during the 2017 cryptocurrency bull run, along with another 40 million DOGECOIN that I sold that year. Even after accounting for a portion of the recovered coins that was awarded to Intelligence Cyber Wizard for their efforts, I still gained a significant financial advantage. Therefore, I am deeply grateful to Intelligence Cyber Wizard, for the swift and successful recovery of my wallet. Their efforts have undoubtedly had a truly transformative impact on my life in the long run. I highly recommend Intelligence Cyber Wizard services if you or someone you know has a wallet that needs hacking and whose password or spending PIN has been lost or forgotten. Contact Intelligence Cyber Wizard via WhatsApp or email. WhatsApp +1 (219) 424-7566 Email: intelligencecyberwizard @ gmail.com Email: intelligencecyberwizard @ cyber-wizard.com Website: https: //intelligence-cyber-wizard.web node.page
-
18.12.25 13:24
Regency Victorian
I was scammed and left penniless, until a cryptocurrency recovery expert helped me. INTELLIGENCE CYBER WIZARD - Cryptocurrency Recovery. I was scammed out of a huge amount of money and, devastated, I started looking for help. Someone recommended an expert and private investigator, Intelligence Cyber Wizard. I emailed him, and as soon as I explained what had happened, he immediately told me it had all been a setup. He put my case together, and within a few days, we got a result: I recovered all my money! Intelligence Cyber Wizard was amazing, professional, and efficient; he guided me through the entire process. I can't thank him and his forensic team enough. I can live again! His contact information is below. WhatsApp +1 (219) 424-7566 Email: [email protected] Email: [email protected] Website: https://intelligence-cyber-wizard.webnode.page
-
18.12.25 20:54
James Robert
I am James Robert from Chicago. Few months ago, I fell victim to an online Bitcoin investment scheme that promised high returns within a short period. At first, everything seemed legitimate, their website looked professional, and the people behind it were very convincing. I invested a significant amount of money about $440,000 with the way they talk to me into investing on their bitcoin platform. Two months later I realized that it was a scam when I could no longer have access to my account and couldn’t withdraw my money. At first, I lost hope that I wouldn't be able to get my money back, I cried and was angry at how I even fell victim to a scam. For days after doing some research and seeking professional help online, I came across GREAT WHIP RECOVERY CYBER SERVICES and saw how they have helped people recover their money back from scammers. I reported the case immediately to them and gather every transaction detail, documentation and sent it to them. Today, I’m very happy because the GREAT WHIP RECOVERY CYBER SERVICES help me recover all my money I was scammed. You can contact GREAT WHIP RECOVERY CYBER SERVICES if you have ever fallen victim to scam. Email: [email protected] or Website https://greatwhiprecoveryc.wixsite.com/greatwhip-site or Call +1(406)2729101
-
18.12.25 20:55
James Robert
I am James Robert from Chicago. Few months ago, I fell victim to an online Bitcoin investment scheme that promised high returns within a short period. At first, everything seemed legitimate, their website looked professional, and the people behind it were very convincing. I invested a significant amount of money about $440,000 with the way they talk to me into investing on their bitcoin platform. Two months later I realized that it was a scam when I could no longer have access to my account and couldn’t withdraw my money. At first, I lost hope that I wouldn't be able to get my money back, I cried and was angry at how I even fell victim to a scam. For days after doing some research and seeking professional help online, I came across GREAT WHIP RECOVERY CYBER SERVICES and saw how they have helped people recover their money back from scammers. I reported the case immediately to them and gather every transaction detail, documentation and sent it to them. Today, I’m very happy because the GREAT WHIP RECOVERY CYBER SERVICES help me recover all my money I was scammed. You can contact GREAT WHIP RECOVERY CYBER SERVICES if you have ever fallen victim to scam. Email: [email protected] or Website https://greatwhiprecoveryc.wixsite.com/greatwhip-site or Call +1(406)2729101
-
18.12.25 21:02
James Robert
This company call GREAT WHIP RECOVERY CYBER SERVICES was honest from the beginning. No false promises – just results. Call:+1(406)2729101
-
18.12.25 21:02
James Robert
I am James Robert from Chicago. Few months ago, I fell victim to an online Bitcoin investment scheme that promised high returns within a short period. At first, everything seemed legitimate, their website looked professional, and the people behind it were very convincing. I invested a significant amount of money about $440,000 with the way they talk to me into investing on their bitcoin platform. Two months later I realized that it was a scam when I could no longer have access to my account and couldn’t withdraw my money. At first, I lost hope that I wouldn't be able to get my money back, I cried and was angry at how I even fell victim to a scam. For days after doing some research and seeking professional help online, I came across GREAT WHIP RECOVERY CYBER SERVICES and saw how they have helped people recover their money back from scammers. I reported the case immediately to them and gather every transaction detail, documentation and sent it to them. Today, I’m very happy because the GREAT WHIP RECOVERY CYBER SERVICES help me recover all my money I was scammed. You can contact GREAT WHIP RECOVERY CYBER SERVICES if you have ever fallen victim to scam. Email: [email protected] or Website https://greatwhiprecoveryc.wixsite.com/greatwhip-site or Call +1(406)2729101
-
20.12.25 16:03
VERONICAFREDDIE809
Earlier this year, I made a mistake that changed everything. I downloaded what I thought was a legitimate trading app I’d found through a Telegram channel. At first, everything looked real until I tried to withdraw. My entire investment vanished into a bot account, and that’s when the truth hit me: I had been scammed. I can’t describe the feeling. It was as if the ground dropped out from under me. I blamed myself. I felt stupid, ashamed, helpless every painful emotion at once. For a while, I couldn’t even talk about it. I thought no one would understand. But then I found someone Agent Jasmine Lopez ([email protected]) ,She didn’t brush me off or judge me. She took my fear seriously. She followed leads I didn’t even know existed, and identified multiple off-chain indicators and wallet clusters linked to the scammer network, she helped me understand what had truly happened behind the scenes. For the first time since everything fell apart, I felt hope. Hearing that other people students, parents, hardworking people had been targeted the same way made me realize I wasn’t alone. What happened to us wasn’t stupidity. It was a coordinated attack. We were prey in a system built to deceive. And somehow, through all the chaos, Agent Jasmine stepped in and shined a light into the darkest moment of my life. I’m still healing from the experience. It changed me. But it also reminded me that even when you think you’re at the end, sometimes a lifeline appears where you least expect it. Contact her at [email protected] WhatsApp at +44 736-644-5035.
-
06.01.26 00:54
justineluscacio
I hope this review gets to as many as possible because I am sure it will save many. On March 15, I received a message on Telegram inviting me to join a Cryptocurrency investment group. At first, I thought it was a harmless invitation. I joined and began to see how a specific crypto and forex trader was helping many people and even gifting out Bitcoin to his loyal followers. I was thrilled; many people in the group were reporting their daily successes and how they were earning a substantial amount. I was jealous; I saw people making a lot of money, but not me. I became furious and decided to contact the group's admin, not realizing I had fallen for their trap. That Telegram channel was a hoax, controlled by an organized team of scammers. Within 3 months of being on that platform, I had given out a whopping 11 Bitcoin in total. I was lost when I was logged out of the investment website and blocked from accessing their Telegram channel. I tried all the means I could think of at that moment, all to no avail. It went from days to weeks, and I still couldn't get back my lost Bitcoin. I was on Medium when I came across a review about digital assets recovery companies. There were quite a few of them, but DuneNectarOnlineExpert caught my attention. I copied their email ( Support @ Dunenectaronlineexpert . Com ), filed a report, and my task was attended to with utmost urgency. After back and forth with this team of cybersecurity experts, DuneNectarOnlineExpert successfully traced the Bitcoin to the scammers' wallet, and it was successfully reclaimed. The team of DuneNectarOnlineExpert was incredibly helpful in recovering my lost Bitcoin. Telegram: T.me/Dunenectarwebexpert WhatApp: +(1252-271-8900)
-
06.01.26 15:05
justineluscacio
I hope this review gets to as many as possible because I am sure it will save many. On March 15, I received a message on Telegram inviting me to join a Cryptocurrency investment group. At first, I thought it was a harmless invitation. I joined and began to see how a specific crypto and forex trader was helping many people and even gifting out Bitcoin to his loyal followers. I was thrilled; many people in the group were reporting their daily successes and how they were earning a substantial amount. I was jealous; I saw people making a lot of money, but not me. I became furious and decided to contact the group's admin, not realizing I had fallen for their trap. That Telegram channel was a hoax, controlled by an organized team of scammers. Within 3 months of being on that platform, I had given out a whopping 11 Bitcoin in total. I was lost when I was logged out of the investment website and blocked from accessing their Telegram channel. I tried all the means I could think of at that moment, all to no avail. It went from days to weeks, and I still couldn't get back my lost Bitcoin. I was on Medium when I came across a review about digital assets recovery companies. There were quite a few of them, but DuneNectarOnlineExpert caught my attention. I copied their email ( Support @ Dunenectaronlineexpert . Com ), filed a report, and my task was attended to with utmost urgency. After back and forth with this team of cybersecurity experts, DuneNectarOnlineExpert successfully traced the Bitcoin to the scammers' wallet, and it was successfully reclaimed. The team of DuneNectarOnlineExpert was incredibly helpful in recovering my lost Bitcoin. Telegram: T.me/Dunenectarwebexpert WhatApp: +(1252-271-8900)
-
06.01.26 16:06
justineluscacio
Successful Bitcoin Recovery Testimonials in Europe, USA, UK, Asia, Canada, South Africa.
-
06.01.26 16:07
justineluscacio
Successful Bitcoin Recovery Testimonials in Europe, USA, UK, Asia, Canada, South Africa. BITCOIN RECOVERY EXPERT USDT RECOVERY EXPERT ETH RECOVERY EXPERT How do I hire a hacker to help me recover my lost funds? How to Recover Money Lost to an Online Scam How to recover lost or stolen cryptocurrency Best recovery experts for cryptocurrency DuneNectarOnlineExpert was incredibly helpful in recovering my lost Bitcoin. Telegram: T.me/Dunenectarwebexpert WhatApp: +(1252-271-8900)
-
06.01.26 16:14
justineluscacio
I hope this review gets to as many as possible because I am sure it will save many. On March 15, I received a message on Telegram inviting me to join a Cryptocurrency investment group. At first, I thought it was a harmless invitation. I joined and began to see how a specific crypto and forex trader was helping many people and even gifting out Bitcoin to his loyal followers. I was thrilled; many people in the group were reporting their daily successes and how they were earning a substantial amount. I was jealous; I saw people making a lot of money, but not me. I became furious and decided to contact the group's admin, not realizing I had fallen for their trap. That Telegram channel was a hoax, controlled by an organized team of scammers. Within 3 months of being on that platform, I had given out a whopping 11 Bitcoin in total. I was lost when I was logged out of the investment website and blocked from accessing their Telegram channel. I tried all the means I could think of at that moment, all to no avail. It went from days to weeks, and I still couldn't get back my lost Bitcoin. I was on Medium when I came across a review about digital assets recovery companies. There were quite a few of them, but DuneNectarOnlineExpert caught my attention. I copied their email ( Support @ Dunenectaronlineexpert . Com ), filed a report, and my task was attended to with utmost urgency. After back and forth with this team of cybersecurity experts, DuneNectarOnlineExpert successfully traced the Bitcoin to the scammers' wallet, and it was successfully reclaimed. The team of DuneNectarOnlineExpert was incredibly helpful in recovering my lost Bitcoin. Telegram: T.me/Dunenectarwebexpert WhatApp: +(1252-271-8900)
-
06.01.26 17:03
Matt Kegan
Reach out to SolidBlock Forensics if you want to get back your coins from fake crypto investment or your wallet was compromised and all your coins gone. SolidBlock Forensics provide deep ethical analysis and investigation that enables them to trace these schemes, and recover all your funds. Their services are professional and reliable. http://www.solidblockforensics.com
-
09.01.26 17:11
VERONICAFREDDIE809
Earlier this year, I made a mistake that changed everything. I downloaded what I thought was a legitimate trading app I’d found through a Telegram channel. At first, everything looked real until I tried to withdraw. My entire investment vanished into a bot account, and that’s when the truth hit me: I had been scammed. I can’t describe the feeling. It was as if the ground dropped out from under me. I blamed myself. I felt stupid, ashamed, helpless every painful emotion at once. For a while, I couldn’t even talk about it. I thought no one would understand. But then I found someone Agent Jasmine Lopez ([email protected]) ,She didn’t brush me off or judge me. She took my fear seriously. She followed leads I didn’t even know existed, and identified multiple off-chain indicators and wallet clusters linked to the scammer network, she helped me understand what had truly happened behind the scenes. For the first time since everything fell apart, I felt hope. Hearing that other people students, parents, hardworking people had been targeted the same way made me realize I wasn’t alone. What happened to us wasn’t stupidity. It was a coordinated attack. We were prey in a system built to deceive. And somehow, through all the chaos, Agent Jasmine stepped in and shined a light into the darkest moment of my life. I’m still healing from the experience. It changed me. But it also reminded me that even when you think you’re at the end, sometimes a lifeline appears where you least expect it. Contact her at [email protected] WhatsApp at +44 736-644-5035.
-
10.01.26 14:28
justineluscacio
I hope this review gets to as many as possible because I am sure it will save many. On March 15, I received a message on Telegram inviting me to join a Cryptocurrency investment group. At first, I thought it was a harmless invitation. I joined and began to see how a specific crypto and forex trader was helping many people and even gifting out Bitcoin to his loyal followers. I was thrilled; many people in the group were reporting their daily successes and how they were earning a substantial amount. I was jealous; I saw people making a lot of money, but not me. I became furious and decided to contact the group's admin, not realizing I had fallen for their trap. That Telegram channel was a hoax, controlled by an organized team of scammers. Within 3 months of being on that platform, I had given out a whopping 11 Bitcoin in total. I was lost when I was logged out of the investment website and blocked from accessing their Telegram channel. I tried all the means I could think of at that moment, all to no avail. It went from days to weeks, and I still couldn't get back my lost Bitcoin. I was on Medium when I came across a review about digital assets recovery companies. There were quite a few of them, but DuneNectarOnlineExpert caught my attention. I copied their email ( Support @ Dunenectaronlineexpert . Com ), filed a report, and my task was attended to with utmost urgency. After back and forth with this team of cybersecurity experts, DuneNectarOnlineExpert successfully traced the Bitcoin to the scammers' wallet, and it was successfully reclaimed. The team of DuneNectarOnlineExpert was incredibly helpful in recovering my lost Bitcoin. Telegram: T.me/Dunenectarwebexpert WhatApp: +(1252-271-8900)
-
11.01.26 03:16
austinjarvis
I lost £75,000 in a Bitcoin scam. Scammers used deepfake videos to make it seem like Elon Musk himself pitched the deal. These deepfakes swap faces onto real people with AI. They look so real you can't spot the trick at first. They drew me in with talk of fast cash. Double your money in weeks, they said. Videos showed Musk explaining simple steps to join. I bit. Sent my Bitcoin bit by bit. First small amounts worked. Then I dumped my full savings. Boom. Funds vanished. No more contact. My bank account empty. Bills piled up. Loans to cover rent and food. Sleep gone. Stress hit hard. Felt like my whole life crashed. A mate saw my pain. He shared his own story from last year. Same scam type. He pointed me to Sylvester, a recovery agent. Reach him at Yt7cracker@gmail . com. Or WhatsApp + 1 512 577 7957. Or + 44 7428 662701. Sylvester got to work fast. Tracked the blockchain trails. Dealt with exchanges. Fought the scammers' tricks. Weeks later, my Bitcoin came back. Even the profits they promised. Debt lifted. Life back on track. If you're hit, contact him now.
-
12.01.26 16:24
VERONICAFREDDIE809
Earlier this year, I made a mistake that changed everything. I downloaded what I thought was a legitimate trading app I’d found through a Telegram channel. At first, everything looked real until I tried to withdraw. My entire investment vanished into a bot account, and that’s when the truth hit me: I had been scammed. I can’t describe the feeling. It was as if the ground dropped out from under me. I blamed myself. I felt stupid, ashamed, helpless every painful emotion at once. For a while, I couldn’t even talk about it. I thought no one would understand. But then I found someone Agent Jasmine Lopez ([email protected]) ,She didn’t brush me off or judge me. She took my fear seriously. She followed leads I didn’t even know existed, and identified multiple off-chain indicators and wallet clusters linked to the scammer network, she helped me understand what had truly happened behind the scenes. For the first time since everything fell apart, I felt hope. Hearing that other people students, parents, hardworking people had been targeted the same way made me realize I wasn’t alone. What happened to us wasn’t stupidity. It was a coordinated attack. We were prey in a system built to deceive. And somehow, through all the chaos, Agent Jasmine stepped in and shined a light into the darkest moment of my life. I’m still healing from the experience. It changed me. But it also reminded me that even when you think you’re at the end, sometimes a lifeline appears where you least expect it. Contact her at [email protected] WhatsApp at +44 736-644-5035.
-
 13:04
Kelvin Alfons
13:04
Kelvin Alfons
Hello everyone. I’d like to share my personal experience from one of the most challenging times in my life. I’m based in Sydney, Australia, and on November 13, 2025, I fell victim to a fraudulent cryptocurrency investment platform that promised substantial financial growth. Believing their claims, I invested a total of $220,000 with the expectation of earning solid returns. However, when I attempted to withdraw my funds, all communication abruptly stopped. My calls were ignored, my emails went unanswered, and I was left feeling completely powerless. Like many others, I had heard that Bitcoin transactions are impossible to trace, so I assumed my money was lost forever. After some time, I discovered information about GREAT WHIP RECOVERY CYBER SERVICES, a reputable digital asset recovery firm. I decided to reach out to them, and to my astonishment, they were able to help me recover the full amount I had lost. I’m sharing my story in the hope that it may help someone else who is going through a similar situation and looking for support. Their contact is, Website: https://greatwhiprecoveryc.wixsite.com/greatwhip-site Email:[email protected] Call: +1(406)2729101
-
13:05
Kelvin Alfons
Hello everyone. I’d like to share my personal experience from one of the most challenging times in my life. I’m based in Sydney, Australia, and on November 13, 2025, I fell victim to a fraudulent cryptocurrency investment platform that promised substantial financial growth. Believing their claims, I invested a total of $220,000 with the expectation of earning solid returns. However, when I attempted to withdraw my funds, all communication abruptly stopped. My calls were ignored, my emails went unanswered, and I was left feeling completely powerless. Like many others, I had heard that Bitcoin transactions are impossible to trace, so I assumed my money was lost forever. After some time, I discovered information about GREAT WHIP RECOVERY CYBER SERVICES, a reputable digital asset recovery firm. I decided to reach out to them, and to my astonishment, they were able to help me recover the full amount I had lost. I’m sharing my story in the hope that it may help someone else who is going through a similar situation and looking for support. Their contact is, Website: https://greatwhiprecoveryc.wixsite.com/greatwhip-site Email:[email protected] Call: +1(406)2729101
-
15:53
VERONICAFREDDIE809
Earlier this year, I made a mistake that changed everything. I downloaded what I thought was a legitimate trading app I’d found through a Telegram channel. At first, everything looked real until I tried to withdraw. My entire investment vanished into a bot account, and that’s when the truth hit me: I had been scammed. I can’t describe the feeling. It was as if the ground dropped out from under me. I blamed myself. I felt stupid, ashamed, helpless every painful emotion at once. For a while, I couldn’t even talk about it. I thought no one would understand. But then I found someone Agent Jasmine Lopez ([email protected]) ,She didn’t brush me off or judge me. She took my fear seriously. She followed leads I didn’t even know existed, and identified multiple off-chain indicators and wallet clusters linked to the scammer network, she helped me understand what had truly happened behind the scenes. For the first time since everything fell apart, I felt hope. Hearing that other people students, parents, hardworking people had been targeted the same way made me realize I wasn’t alone. What happened to us wasn’t stupidity. It was a coordinated attack. We were prey in a system built to deceive. And somehow, through all the chaos, Agent Jasmine stepped in and shined a light into the darkest moment of my life. I’m still healing from the experience. It changed me. But it also reminded me that even when you think you’re at the end, sometimes a lifeline appears where you least expect it. Contact her at [email protected] WhatsApp at +44 736-644-5035.
Для участия в Чате вам необходим бесплатный аккаунт pro-blockchain.com
Войти
Регистрация
Авторизация
Регистрация
Похожие новости
Финансовые рынки от TradingView
Подпишись на telegram канал и узнавай первым обо всех новостях